Dynamic Access Control of Sensitive User Data
Who should have access to certain sensitive data often depends on dynamic contextual information: A teacher should only be able to access their student’s records and only for the duration that the student has classes with them; a doctor, only their patient’s; or in the simplest case, a user should only have access to their own data. Access control should be dynamic: based on conditional rules encapsulated during API authorization, and enforced based on zero trust principles.
Increasing the privacy and security of sensitive data starts with a zero trust approach. In a zero trust model, no user or service has access to sensitive data unless access is explicitly granted.
However, security controls for many systems fail to properly restrict access to a subset of users. These controls lack contextual information to determine when to reveal sensitive data. Because they can’t take business relationships into account (such as a nurse's need to simultaneously care for multiple patients) to get data access configured correctly, many companies grant overly-broad access to sensitive data. As a result, their backend systems are exposed to more sensitive data than they technically need, increasing those companies’ security risk and compliance scope.
In this post we’ll break down the limitations and challenges companies face with traditional methods of managing sensitive data, and then we’ll show how to address these challenges using context-aware authorization.
The Limits of Traditional Access Control for Sensitive Data
In this section, we discuss the following common approaches to the management of sensitive data and the limitations of using those approaches:
- The Security Fence
- Lock Down and Synchronize
- De-identify via Tokenization
The Security Fence
In many systems, access is controlled through a security fence (or network perimeter), but once someone is inside the fence, they have access to everything (see image below). The false assumption this basic security approach makes is that if a client, service, or user is within the fence, they should be there, and can be trusted with access to sensitive systems and data.
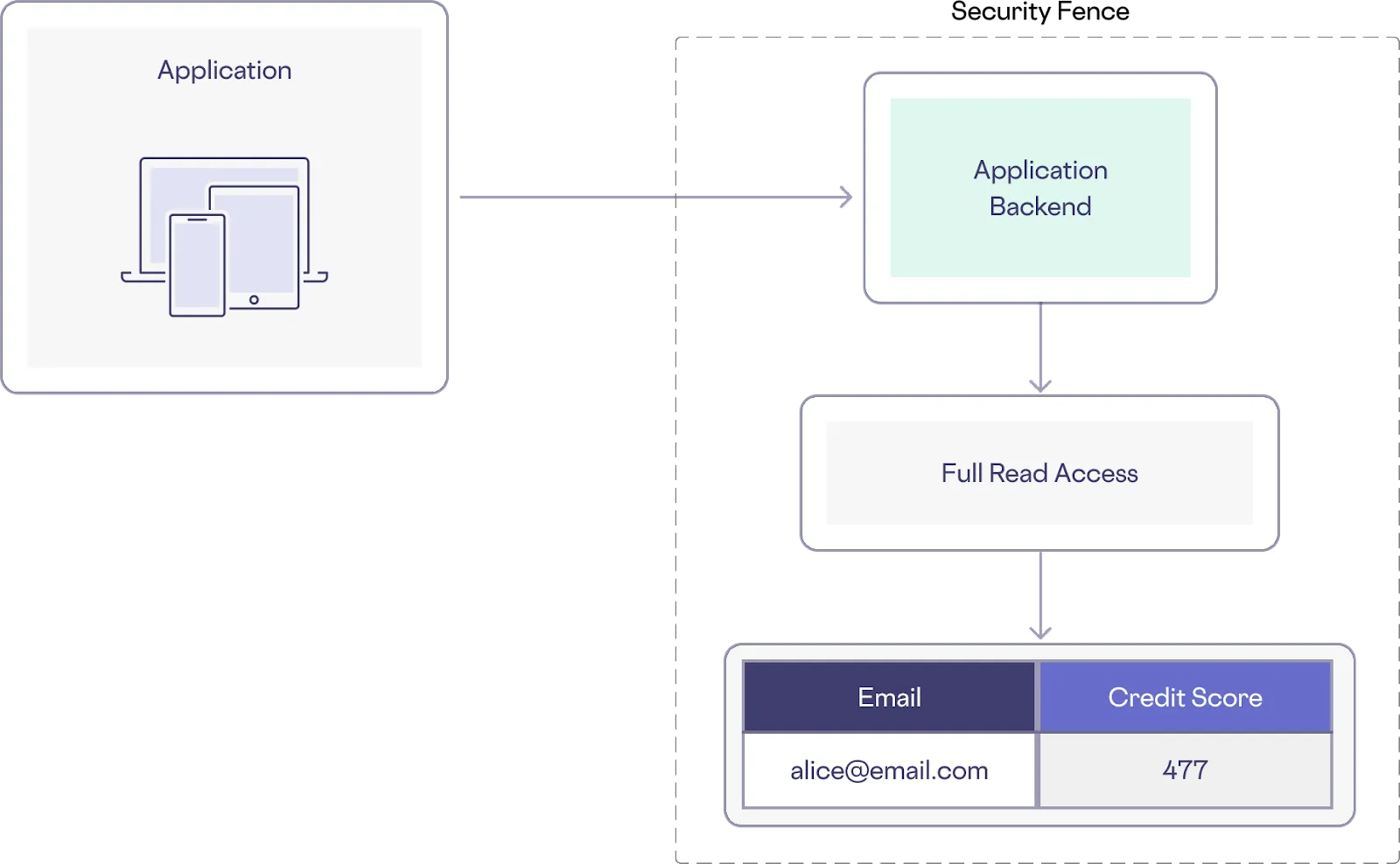
This approach provides limited security, since a single compromised app or user account can have very broad access to sensitive data. The limitations of this approach has led to the growing adoption of zero trust architecture.
Lock Down and Synchronize
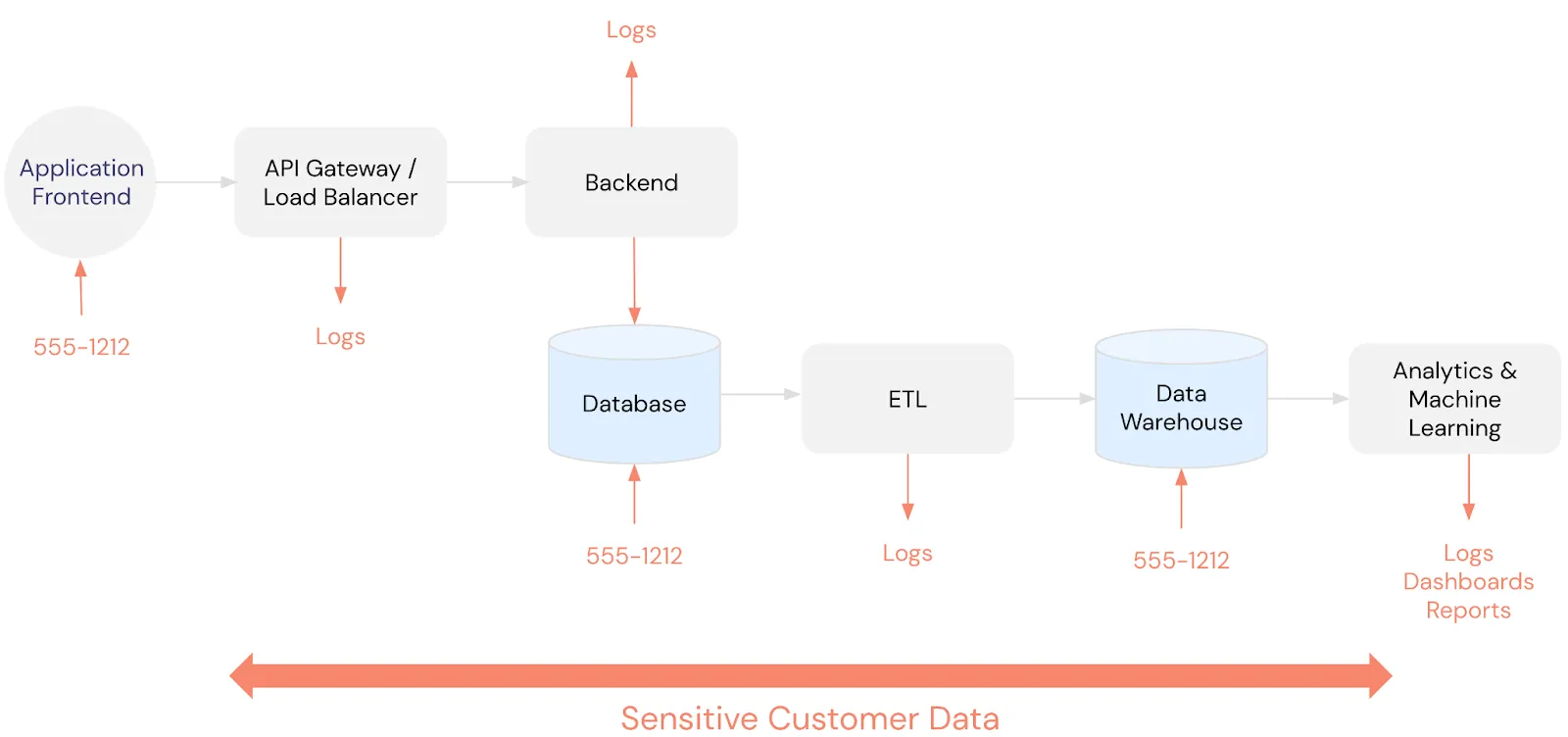
Alternatively, sensitive data is locked down to specific users or services. Access is controlled through a data governance layer specific to the storage medium.
For example, the application database will have certain sensitive data and uses one application-specific governance system to control access while the data warehouse has slightly different data and uses different application-specific rules.
The business is forced to try to keep all of these rules in sync across all these different disparate systems. But since sensitive customer data tends to end up everywhere, this quickly becomes an intractable problem (see image below).
De-identify via Tokenization
Tokenization is a widely used technique for substituting sensitive data for non-sensitive tokens. During data collection, sensitive data elements are swapped for tokens. These tokens are stored by your downstream services and later exchanged for the original values through the process of detokenization, as shown below:
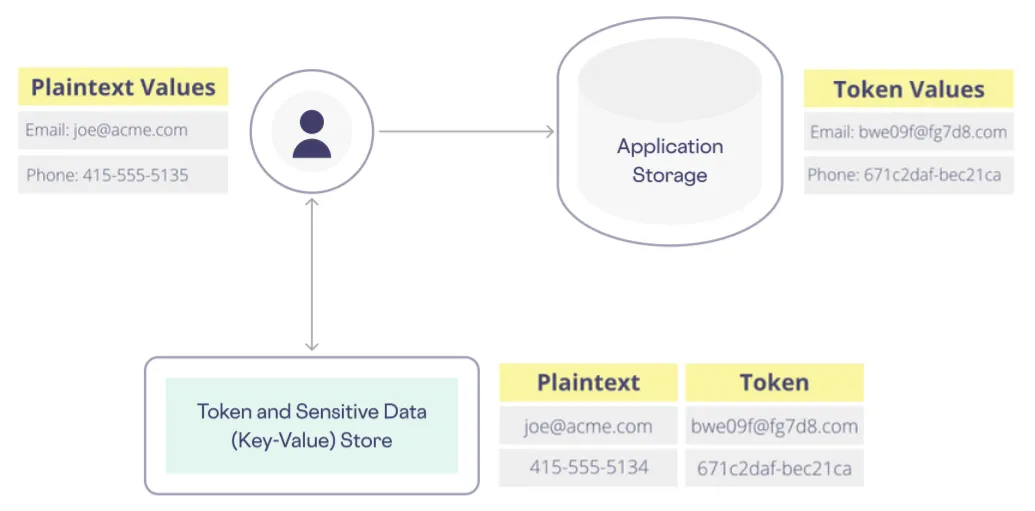
However, as long as you have a valid API key, traditional tokenization doesn’t restrict access to sensitive data. The tokens and API key lack contextual information to restrict access based on use case, giving each user and service overly-broad access to sensitive data.
If you have a token and an API key, you can exchange that token for the original sensitive data, even if it's outside the scope of what you legitimately need. This type of tokenization system is very simple to understand and relatively easy to implement, but this type of tokenization by itself lacks contextual awareness to enforce granular, dynamic access controls.
What Traditional Access Control Methods Miss
Above we discuss some of the limitations of these approaches to access control, but the gaps left by these approaches are complex and subtle, so let’s take a bit more time to look at a few key limitations of these methods:
- Data Maximization
- Compliance Scope and Attack Surface
- External Relationship Modeling
- Auditability
Data Maximization
To protect sensitive data after tokenizing it, most tokenization vendors provide solutions for detokenizing data from the backend. This adds a layer of security as someone would need to get access to your backend in order to gain access to the tokens.
However, with this model and the data governance limits of traditional tokenization, there will always be a role with permissions to detokenize all tokens and retrieve sensitive data for all customers. This model assumes that anyone within the backend system is allowed to be there, similar to the security fence discussed previously, and just like a security fence, it doesn’t align with zero trust principles.
As demonstrated by many data breaches, like the Optus breach, attackers are often able to gain access to internal systems. Without a zero trust model, the attacker is trusted once they penetrate the security fence and can now detokenize any information they want.
Compliance Scope and Attack Surface Minimization
By relying on detokenization from your backend and then passing the plaintext values to your frontend, you are exposing your backend systems to sensitive customer data, increasing your compliance scope.
On the other hand, securing sensitive data by applying strong data governance to both your frontend and your backend infrastructure reduces your compliance scope and provides optimal security.
Ideally, you re-identify (or detokenize) sensitive data as late as possible in the data lifecycle – for example, at render time on the frontend system. This reduces your total attack surface and keeps your infrastructure out of compliance scope.
External Relationship Modeling
There are many applications where a type of user should have access to some portion of a collection of other users’ data based on a relationship between those users. For example, a teacher accessing their student’s records, a doctor accessing patient records, or a lawyer accessing their client records.
These relationships are typically managed and understood by the application. Governing these business rules across different disparate systems is very difficult and hard to maintain.
With a simple key-value based tokenization service, the system exists without any model for these relationships, so it has no way to enforce security using these relationships. So even if you’ve defined a role for teachers that determines their access to student information in various contexts, the tokenization system can’t restrict access to only the student records within the teacher’s class.
Auditability
Audit logs tracking all access to sensitive data are required by certain compliance regulations and are needed to maintain a good security posture. However, since traditional systems lack context about the specific user that’s performing the detokenization request, the logs are lacking essential information about who made each data request.
From an audit report perspective, lack of context-awareness means it’s difficult or impossible to tell the difference between a legitimate request, and a malicious one.
This might sound like a minor detail, but opaque audit logging poses severe risks to your data security. Not only can audit logs that lack context make it difficult or impossible to gain or maintain compliance with standards like PCI DSS, GDPR, and SOC2, such audit logs also make it difficult to detect the early stages of a breach of your infrastructure before it expands into a much more damaging incident.
Going Beyond Simple Access Control
While many tokenization systems rely on a key/value store similar to a hashtable, one key feature of Skyflow Data Privacy Vault is a schema-based tokenization system. Skyflow’s secure storage layer works like a relational database, so user data is stored in a table like the following:
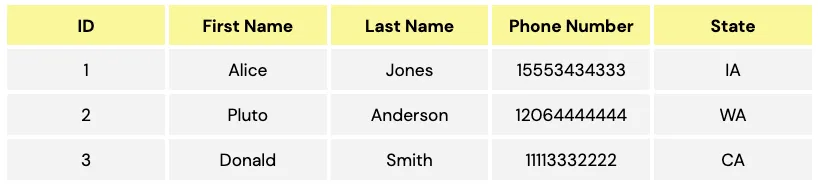
In legacy tokenization systems, access is essentially a boolean (true or false) value. You either have access, or you don’t. The advantage of a schema-based approach to tokenization access controls is that the vault has a true understanding of the end user record and how the different columns in a table relate to each other in the context of that record. And because its schema is relational, it can model relationships and enforce security based on those relationships.
The governance engine enforces fine-grained and dynamic access control. Using Skyflow’s Policy Based Access Control model, you can author policies that control access at the column level, as well as at the row level.
The above policy grants access to user phone numbers only in those rows where the user’s state has a value of CA.
Expressions like these give you a powerful yet simple syntax to control access to vault data based around the principles of least privilege. However, this approach is limited to static values. In the above example, the state is essentially hardcoded to the string value CA.
Dynamic Access Control with Context-Aware Authorization
API authentication in Skyflow is handled using service account keys. A service account is associated with a role, which is associated with one or more policies.
With each API call, Skyflow authenticates the call and also checks the authorization for the data request based on the policies associated with the service account’s role. This way, someone that should only be able to view user records within the state of California can never access data for someone in, say, New York.
With context-aware authorization, a Skyflow bearer token can carry an additional claim for context populated dynamically at the time of authentication.
For example, in the image below, the frontend application talks to the backend system (1) to request a bearer token. The backend retrieves the context for the authenticated end user from the application data store (2). This could be something as simple as the user ID for the frontend data requestor.
The application backend authenticates the service account with Skyflow with the user context (3). The Skyflow backend returns a context-aware bearer token to the backend server (4). The application backend forwards the context-aware bearer token to the frontend in response to the original request (5). The frontend requests to detokenize data using the context-aware bearer token and the vault validates the bearer token, extracts the context and enforces access control based on the defined policy (6).
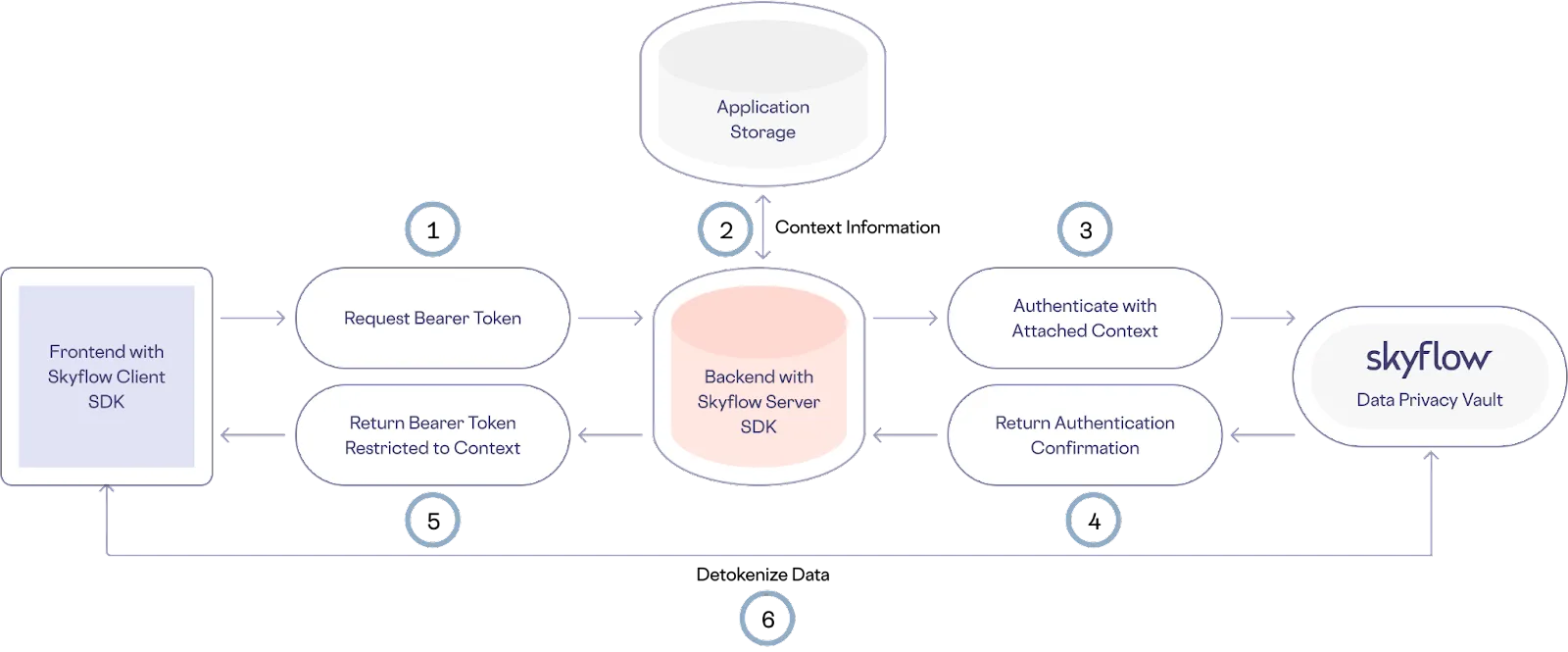
The context parameter can later be extracted and evaluated dynamically for each request, according to the policy rules you create. This connects your business rules for governing data access and your understanding of what a user should be able to access to the data stored within Skyflow Vault.
The Problems that Context-Aware Authorization Solves
The introduction of context-aware authorization and context-aware policies helps address the limitations of traditional approaches to data governance and tokenization.
First we’ll review how context-aware authorization solves these problems, and then discuss the use cases enabled by context-aware authorization:
- Data Minimization Instead of Maximization: Passing in a context as part of authorization means that you can provide a context value based on your own application’s authorization system, such as a user ID. Then you can easily restrict record access based on your understanding of who the user is rather than granting access to all data when reading sensitive data.
- External Relationships Respected: You can ensure that relationships (teacher-student, doctor-patient, etc.) are respected using context-aware authorization by passing in context like a teacher’s ID and creating policy controls that are based on that ID. Your business logic for data access can easily be carried over from your backend system into the vault, giving you the security of the vault while respecting the logic of your application and avoiding the headaches of maintaining duplicative policies.
- Reduced Compliance Scope: The reason detokenization usually takes place in backend systems is to help reduce the risk of a token being leaked, but that increases your compliance scope. With context-aware authorization, detokenization can actually take place on your frontend systems because you can now guarantee that the tokens the user is accessing actually correspond to the data that they’re authorized to access. This significantly reduces your compliance scope and insulates your entire backend infrastructure from data privacy and data security concerns.
- Context-Aware Audit Logs: Auditing or accounting is the third pillar in the AAA (Authentication, Authorization, Accounting) security framework. Thorough auditing helps companies monitor data access and mitigate potential data breaches and misuses of data access policies. With Skyflow’s audit logging features, you can track all requests that are made to Skyflow APIs, including policy updates and data access requests. With context included in authorization and tracked in audit logs, you can now see who is actually making requests to access sensitive data. This allows you to not only determine that a particular service requested access to a record, but that a particular user requested access, making it easier to detect suspicious activity early.
Context-Aware Authorization Use Cases
There are many use cases for context-aware authorization. Below, we discuss a few interesting examples, from controlling access to a user’s own data to basing access on a business relationship between the data owner and requester.
Use Case #1: Accessing Only Your Own Record
One of the primary use cases for context-aware authorization is to restrict access to records explicitly owned by the requesting user.
To do this, the context set during authentication will be the requesting user’s ID, similar to the prior diagram. Within the Skyflow Vault, a policy is set where access to records have a row-level restriction based on the passed-in context, in this case the user ID.
During a data request, the context is taken into account when evaluating what data the user has access to, as shown below.
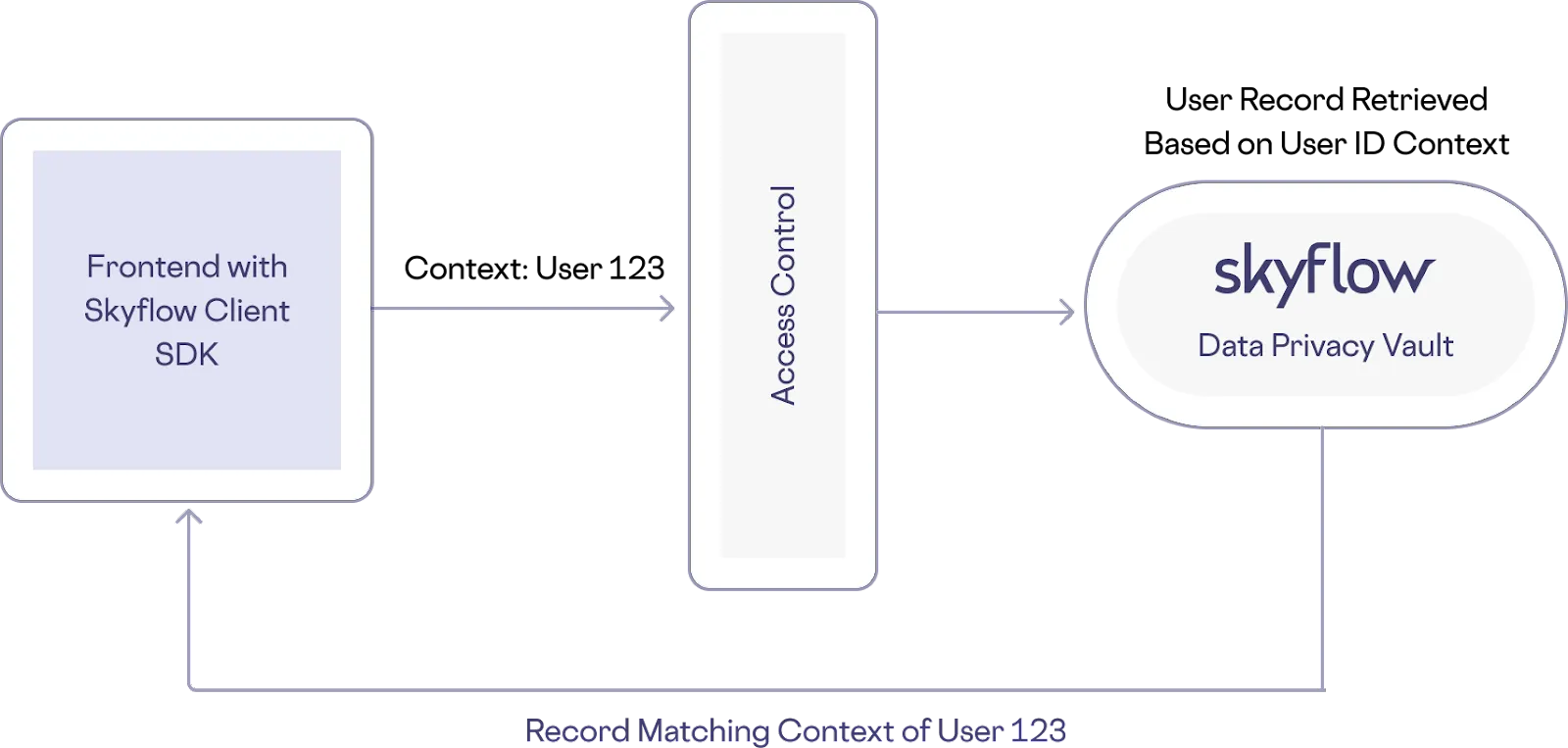
With this more secure and restrictive approach, even if a malicious actor somehow acquired a bearer token, they’d have very limited access to the sensitive data, significantly reducing the scale of a data breach.
Use Case #2: Teacher Accessing Student Records
One of the limitations of a traditional tokenization system is that it can’t take external relationship information into account when evaluating access requests. The solution is to use context defined by student IDs and teacher IDs to determine which teachers can access data about which students using a relational ID mapping in Skyflow Vault. Context-aware authorization solves the problem of needing to map data access to contextual factors, as shown below.
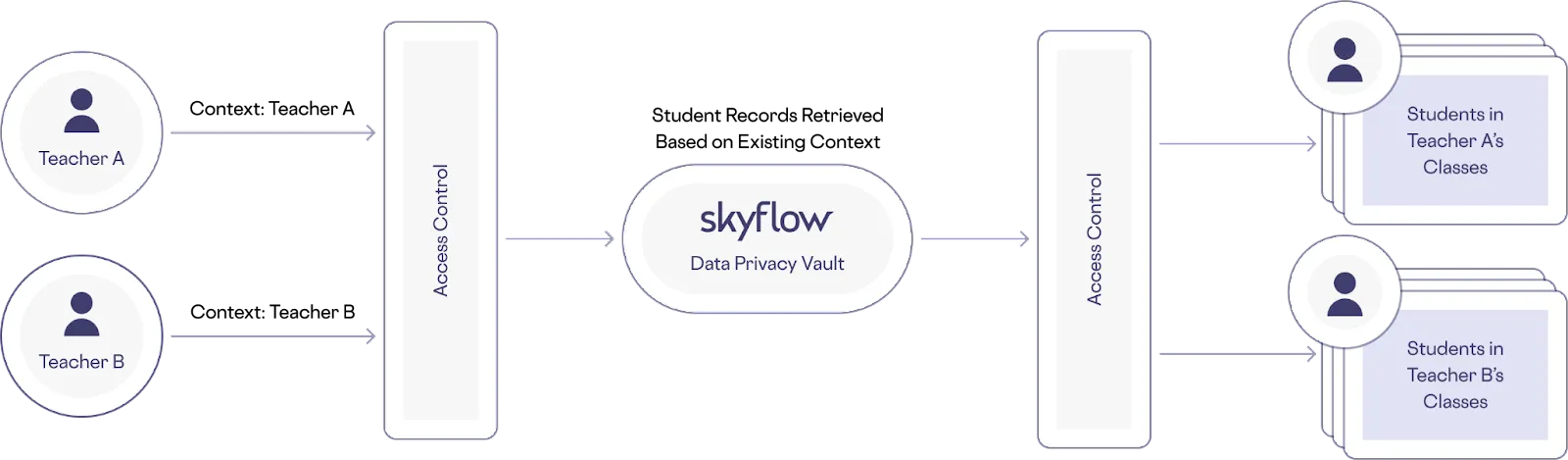
Use Case #3: Transient Customer Support Queue Management
Similar to teachers and students, with customer support agents, ideally the user data they have access to is restricted to their current customer queue. You can support these restrictions with a combination of a context-aware policy and a transient field. Using this approach drastically reduces the potential for damage if customer support agent credentials are stolen.
During authentication, a context representing the customer support agent ID is passed along as a claim. The access policy uses the context to evaluate access based on whether the agent ID exists for a given user’s record.
You can configure access to expire automatically by configuring the agent ID as a transient field with a time limit of 24 hours. This means the agent ID value will automatically be removed after 24 hours, expiring access to the associated records.
This significantly reduces the scale of a potential breach should malicious actors gain support agent login credentials, a common attack vector seen in data breaches. With context-aware authorization and transient fields, even if an attacker steals the agent’s credentials, they’ll only have access to the handful of records in the support queue, and access will automatically expire. If Robinhood had been using this combination of features, it would have prevented the breach of millions of records when their support agent credentials were compromised.
Relationship Information Stored Outside the Vault
As described in the examples above, the relationship between the data requester and the data subject is stored within the Skyflow Vault, whether the end user is accessing their own data or an agent is requesting information for a customer. However, there are many business use cases where these relationships might be stored outside of the vault.
This is often the case when the relationship is very dynamic. For example, let’s say that you’re working for a medical clinic that wants to restrict each doctor’s access to just the patients they work with.
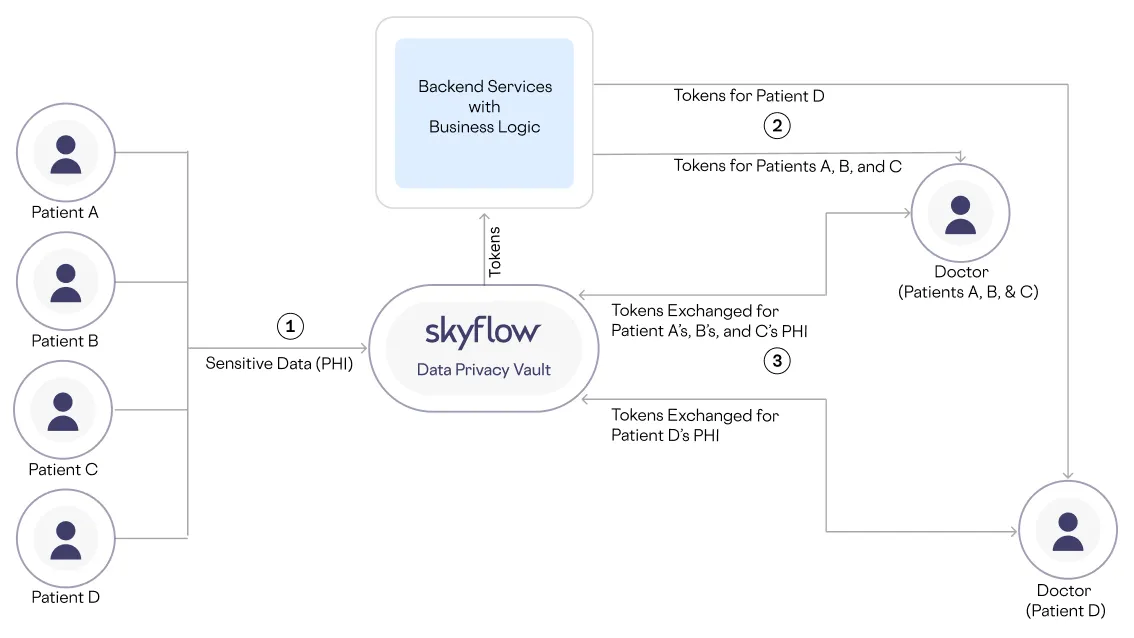
In such cases, you could configure your backend to extract the right set of tokens based on your business logic, which determines the access control rules between the data requester and the data subject. Skyflow supports cryptographically signing tokens with additional context (based on doctor-patient relationships) and a time-to-live (or transient field) setting in your backend. This secures the use of these tokens before they are forwarded to your frontend client for detokenization.
So, you could provide secure, privacy-preserving access to patient data by using Skyflow-generated tokens to create and distribute signed data tokens based on doctor-patient relationships. This restricts a doctor’s sensitive data access to just those patients who they provide care to. And, this approach lets you manage this relationship outside of Skyflow in your existing backend services (no need to sync multiple ACLs).
Here’s how it works:
- Each patient’s PHI is tokenized, with sensitive data values stored in Skyflow and Skyflow-generated tokens stored in the medical clinic’s backend services and used to create signed data tokens.
- The clinic’s backend services generate signed tokens using a context specific to the doctor and restricted to patient PHI based on doctor-patient relationships. The signed tokens are sent to a frontend app.
- Doctors access patient PHI from the frontend app, which exchanges the signed tokens for sensitive data stored in Skyflow.
You can see the resulting architecture, and each of these steps, below:
Final Thoughts
Traditional methods of managing access control to sensitive information are severely limited. They lack the context required to provide dynamic access control.
Simplistic approaches to this problem either give full access to data or give very limited access. Companies end up duplicating access control policies across multiple systems and attempt to keep them in sync.
Additionally, traditional tokenization systems rely on protecting tokens by detokenizing data in backend services, increasing compliance scope and leading to a data maximization problem.
Context-aware authentication addresses the limitations of traditional approaches to protecting sensitive data. It helps you mitigate the risks of handling sensitive data by implementing principles of zero trust and enabling you to dynamically control access based on contextual information. This improves your security posture and reduces your compliance scope when it comes to revealing sensitive data in your frontend application.
To see this in action, join us for our next live demo and Q&A session.