
Generative AI Data Privacy with Skyflow LLM Privacy Vault
The growing use of ChatGPT and similar generative AI technologies is raising data privacy concerns with businesses and regulators. So, how can your business enjoy the benefits of using LLM-based AI systems, while protecting sensitive data?
As the use of GPT (Generative Pre-trained Transformer) models continues to grow, it’s more important than ever to prioritize privacy and data protection. GPTs are powerful large language models (LLMs) that can generate text similar to what a human might write based on inputs and data already present in their model and publicly available on the internet.
But, as companies like Samsung recently discovered, using LLMs without appropriate safeguards can lead to sensitive data leakage. Incidents like these highlight the importance of safeguarding sensitive information when using generative AI technology.
In this post, we’ll look at how LLMs handle sensitive data, and the data privacy issues that companies face when using LLMs. We’ll also explore how using Skyflow LLM Privacy Vault provides a data privacy solution for LLMs that can scale to meet the needs of any business.
What are the Data Privacy Risks of Using LLMs?
Sensitive data, such as internal project names, dates of birth, or social security numbers can flow into LLMs in several ways, depending on the use case, the type of model, and the nature of the data.
Sensitive data generally flows into LLMs via the following types of inputs:
- Training Data: LLMs are typically trained on large amounts of text data, which could potentially include sensitive information such as personally identifiable information (PII), financial information, health data, or other confidential information. If this training dataset is not properly anonymized or redacted, sensitive data within this dataset will flow into the model and can later be potentially exposed to other users when they generate content using that model.
- Inference from Prompt Data: AI systems like ChatGPT are designed to generate text based on user-provided prompts. As with training data, if these prompts contain sensitive data it then flows into the model, where it can be used to generate content that exposes this data.
- Inference from User-Provided Files: In some cases, users might provide documents or other files that contain sensitive data directly to LLM-based AI systems like content generators, chatbots, language translation tools, and other applications and services. As with training data and prompt data, if these user-provided files contain sensitive information, it flows into the model and is exposed to unauthorized users when they generate content.
Learn how to protect sensitive data in AI applications. Download whitepaper →
Regardless of the type of input, LLMs break down inputs into smaller, more manageable units called LLM tokens, and these tokens are then stored within the model. When sensitive data flows into a model this data is similarly broken down into LLM tokens. As an LLM is trained, it learns to recognize and generate patterns using sequences of LLM tokens, rather than by using the original plaintext data.
For example, when a user inputs a phrase containing their phone number, that data is converted into LLM tokens as part of the model training workflow, as shown below:
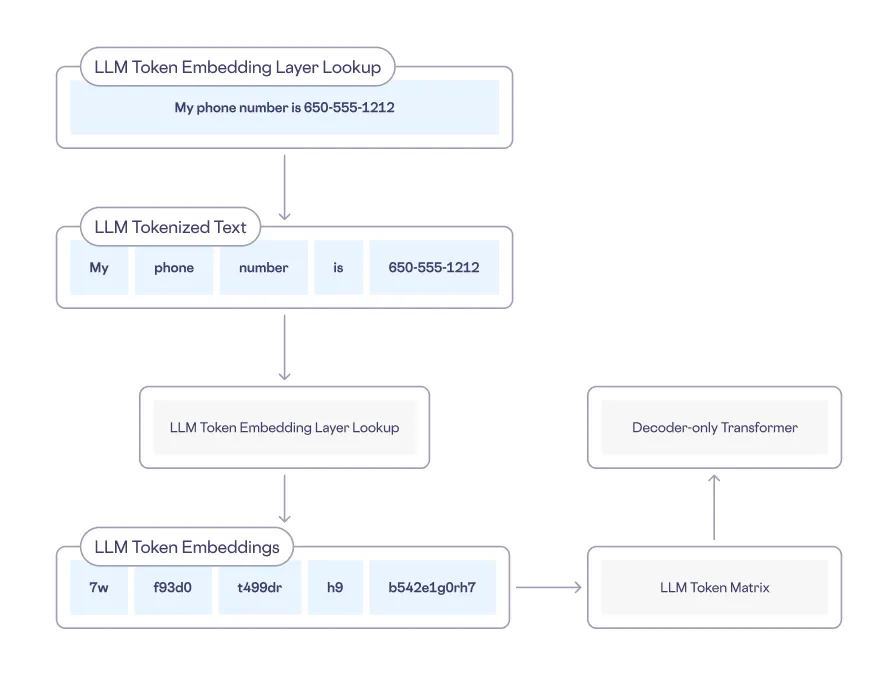
Added to the Model
During training, LLMs analyze patterns and relationships between input LLM tokens to predict the next token in a sequence. When generating text, LLMs utilize input LLM tokens to create longer sequences, imitating human writing style. If sensitive data enters the model, it is processed in the same way, posing a risk to data privacy.
While LLM-based AI systems are exciting and likely to change and improve how work is done across many industries, there are definite privacy challenges when using LLMs that everyone needs to be aware of.
Learn how to protect sensitive data in AI applications. Download whitepaper →
How Does Skyflow Address LLM Privacy Concerns?
Skyflow LLM Privacy Vault offers comprehensive privacy-preserving solutions that let companies prevent the leakage of sensitive data into LLMs, addressing privacy concerns around LLM training (including multi-party model training) and inference from user inputs:
- Model Training: Skyflow enables privacy-safe model training by excluding sensitive data from datasets used in the model training process.
- Multi-party Model Training: Skyflow supports multi-party training so that multiple parties (i.e., multiple businesses or individuals) can de-identify sensitive data from their datasets and then build shared datasets that preserve data privacy.
- Inference: Skyflow also protects the privacy of sensitive data from being collected by inference from prompts or user-provided files.
- Integrated Compute Environment: Skyflow LLM Privacy Vault seamlessly integrates into existing data infrastructure to add an effective layer of data protection. Skyflow LLM Privacy Vault protects all sensitive data by preventing plaintext sensitive data from flowing into LLMs, and only reveals sensitive data to authorized users as model outputs are shared with those users.
Skyflow LLM Privacy Vault de-identifies sensitive data through tokenization or masking and also provides a sensitive data dictionary that lets businesses define terms that are sensitive and should not be fed into LLMs. LLM Privacy Vault also supports data privacy compliance requirements, including data residency.
Before looking more closely at the solutions provided by LLM Privacy Vault, let’s look at how Skyflow de-identifies sensitive data.
De-identification of Sensitive Data
Skyflow identifies sensitive data elements and prevents these data elements from leaking into LLMs by either redacting them completely, or by converting them into Skyflow-generated tokens that act as “stand-ins” for plaintext sensitive data. Skyflow-generated tokens used to protect sensitive data from LLMs are deterministic, meaning that a given sensitive data value will consistently tokenize into the same token string. An LLM can handle Skyflow-generated tokenized values the same way it handles plaintext sensitive data.
You can apply this approach to protect sensitive data included in datasets used for model training, and you can also apply it to protecting sensitive data included in prompts, files, or other content that users provide to an LLM
When an LLM generates a response, the Skyflow-generated tokens are detokenized as the LLM response is sent to the user, replacing these tokens with the original sensitive data elements. Only authorized users are permitted to detokenize plaintext sensitive data that’s included in the LLM’s response because of the fine-grained access controls configured in the vault.
Sensitive Data Dictionary
Skyflow LLM Privacy Vault includes a sensitive data dictionary that lets you define which terms or fields your business considers to be sensitive to prevent your LLM from accessing these data types.
For example, if your company wants to keep the name of a new project confidential, you can define the "Project Name" field as sensitive in the sensitive data dictionary. This custom definition prevents the project name from being used in any data processed by an LLM and keeps it confidential, protecting your company's IP and maintaining secrecy – and, your company’s competitive edge.
Data Residency and Compliance
Skyflow is deployed in a wide variety of locations and is designed to ease compliance with data privacy laws and standards, including data residency requirements. Skyflow LLM Privacy Vault is built on our global data privacy vault infrastructure that is available in over 100 countries, so businesses that use LLMs can meet data residency requirements by storing sensitive data in vaults located in their chosen country or region.
With Skyflow, your business can isolate, protect, and govern sensitive data without sacrificing data use. Isolating sensitive data in Skyflow LLM Privacy Vault also gives your company a sensitive data audit trail, and the ability to implement clear and comprehensive data retention policies that automate the deletion of sensitive data when it’s no longer needed.
Let’s take a closer look at how Skyflow integrates with LLM-based AI systems.
Skyflow LLM Privacy Vault
You can integrate Skyflow LLM Privacy Vault with an LLM-based AI system using a simple yet sophisticated architecture that prevents sensitive data from reaching LLMs.
Here’s a high-level overview of how this could work in the context of the model training datasets and user inputs used by LLMs:
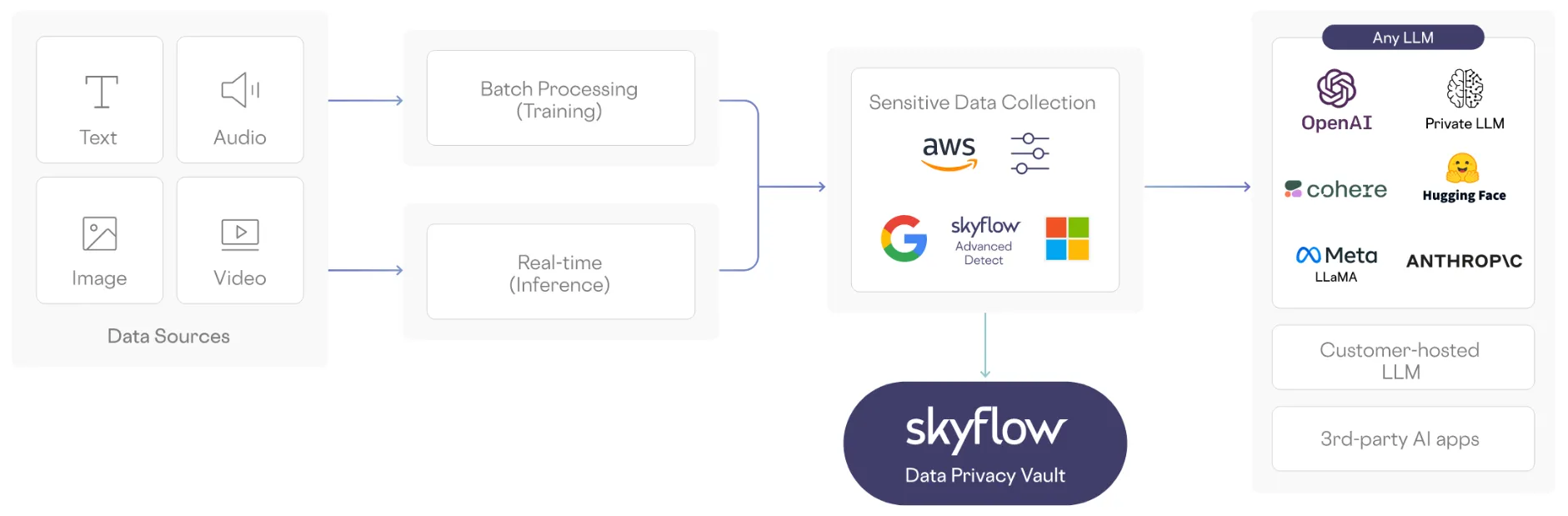
Privacy-preserving Model Training
As mentioned previously, LLMs are typically trained on large amounts of data. Without proper safeguards, it’s easy for sensitive PII or other sensitive data to leak into a model training dataset.
To address this potential risk, all training data flows through Skyflow, where sensitive data is identified and stored within the vault. Skyflow filters out plaintext sensitive data from the training dataset during data ingress to prevent this data from reaching LLMs during model training.
The plaintext sensitive data that’s identified by Skyflow is stored in the vault and replaced by de-identified data that’s sent to its destination in databases, streams, files, etc. where it can then be used for model training.
With plaintext sensitive data stored in Skyflow, LLM training can proceed as normal, with a de-identified and privacy-safe dataset.
Multi-party Training
Multi-party training occurs when multiple parties (i.e., companies) pool data into a shared dataset for purposes of model training. With Skyflow LLM Privacy Vault, companies can de-identify sensitive data to prevent its inclusion in shared model training datasets. Skyflow also lets companies define which types of information are sensitive using custom definitions so that they can protect the privacy and security of their proprietary data and keep that data out of shared datasets – and out of shared LLMs.
For example, let's say that your company is running a joint venture with another company. The joint venture will need to use a shared LLM that’s trained on a shared dataset. But, both you and your joint venture partner need to protect sensitive data like internal project names and customer PII.
You can use an architecture like the following to support multiparty LLM training without exposing sensitive data:
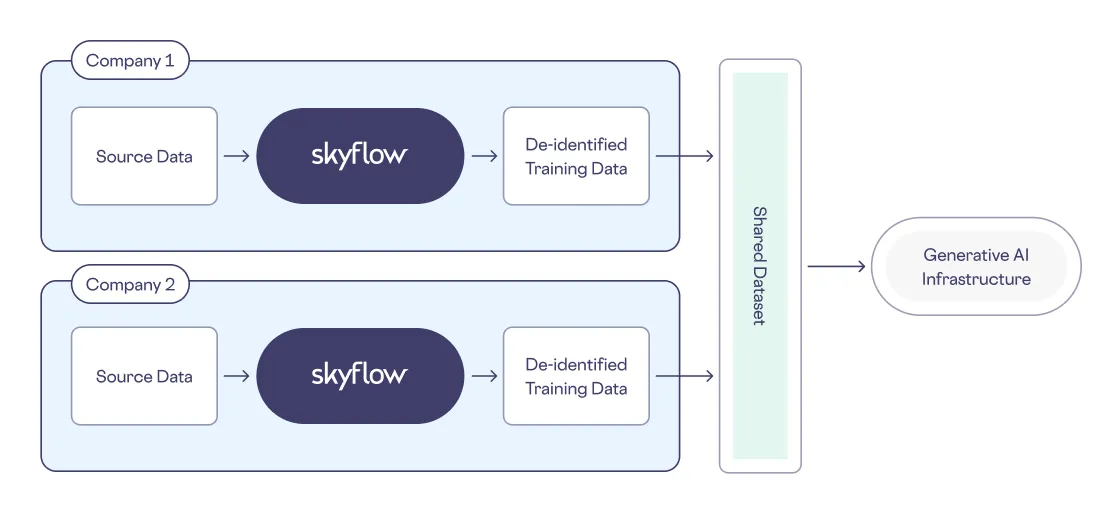
LLM Training
Privacy-preserving Inference
Users interact with LLM-based AI systems in a variety of different ways, with the most popular one being a front-end UI that handles user interactions with an LLM-based AI system such as a chatbot, app, or web interface. Users can also upload files to LLM-based AI systems. In both cases, LLMs-based AI systems often use inference to add any sensitive data provided to them to their models, unless that data is first de-identified.
To detect and tokenize sensitive data, Skyflow intercepts data flows between the UI and the LLM using Skyflow APIs, SDKs, or Skyflow Connections.
Here’s how input data flows in this example architecture:
- Input and De-Identification: User input is sent from the front-end UI directly to Skyflow. Skyflow detects sensitive data that’s included in this input data according to the fields defined in the sensitive data dictionary and replaces this sensitive data with deterministic tokens while storing the plaintext sensitive data securely within the vault.
- Clean Input to LLM: De-identified data is sent as input data to the LLM-based AI system.
- Return Plaintext Sensitive Data in Generated Text to User: Skyflow-generated deterministic tokens from the LLM response are replaced with plaintext sensitive data (based on defined data governance policies) and returned to the user in the context of LLM-generated text.
Because a Skyflow-generated deterministic token replaces each piece of sensitive data, referential integrity is preserved throughout this operation. As you can see, this workflow protects the privacy of sensitive data end-to-end while letting you make use of LLM-based AI systems.
Final Thoughts
Protecting data privacy in LLMs is essential to help ensure that this technology is used in a responsible and ethical manner. By using Skyflow LLM Privacy Vault, companies can protect the privacy and security of sensitive data, protect user privacy, and retain user trust when using LLM-based AI systems.