LLM Data Privacy: How to Implement Effective Data De-identification
As customers race to build more domain specific LLMs, organizations are looking to leverage large proprietary datasets to train powerful models. However, many of these large training datasets contain sensitive personally identifiable information (PII) like names, email addresses, financial data, health records, and more.
Using this sensitive data to train an LLM raises significant data privacy concerns and compliance risks. In addition to this, there's a renewed scrutiny being placed on how models are developed in the US and EU. This makes it even more imperative to ensure that organizations are using appropriate datasets for training and do not leak sensitive information into the LLM.
The solution then is to de-identify sensitive data before using it to train LLMs. Data de-identification protects an individual's or an organization's privacy by removing sensitive information such as PII and other data elements from datasets. This allows organizations to reap the benefits of machine learning while preserving data privacy.
In this post, we’ll look at different strategies for de-identifying sensitive data when training LLMs, how the type of data you’re processing introduces different challenges, and how Skyflow is helping a leading healthcare company build privacy-safe LLMs using our approach to data de-identification.
Let’s start by taking a look at some of the common approaches to de-identification.
Learn how to protect sensitive data in AI applications. Download whitepaper →
Common Data De-identification Techniques
There are several techniques that can be used for de-identifying data:
- Tokenization - This involves substituting sensitive data elements (like credit card numbers) with non-sensitive placeholder tokens that have no exploitable value. The tokens can be used in place of the actual data for training purposes.
- Hashing - Hashing functions take input data and generate a fixed-size alphanumeric string representing the original data. Hashing can de-identify data, but is not ideal for machine learning since it loses the original data's structure and format. The FTC recently ruled that hashing is not a mechanism to make your data anonymous.
- Masking - With masking, portions of sensitive data are obscured or removed. For example, only showing the last four digits of a credit card number.
- Generalization - Replacing precise data values with more general representations. For example, providing just the year instead of a full birth date.
- Differential Privacy - This technique adds calculated noise to datasets, allowing broader insights across the dataset while obscuring individual data points.
The optimal de-identification approach depends on the specific use case and requirements around preserving data utility and format. For example, tokenization may be preferred when the original data's format and structure needs to be maintained for model training.
Importantly, de-identification should be done in a centralized way before the data is used for training machine learning models.
In this article we will explore some of the considerations around de-identifying sensitive information in training data.
What Kinds of Data is Used for Training?
As we explored in a previous blog post about the prevalence of unstructured data, most of the data in the world is unstructured data (logs, emails, audio calls, images etc) and this is what is mostly used for training.
Unsurprisingly, unstructured data is rather hard to wrangle with as sensitive information can be embedded in many different places. Compounding this problem even more, is the data quality itself - e.g audio recordings are notorious for poor quality, low quality images. Textual information can contain varied sensitive information which might be hard to discern.
What Are the Challenges?
As we briefly alluded to in the previous section, de-identifying sensitive information from unstructured data is fairly complex. This is further exacerbated by the completely different formats where unstructured data can exist - audio recordings, chat transcripts, logs, pdfs etc.
General Challenges for All Data Sets
The primary challenge before you set out on this task is, you need to know what kinds of sensitive information are actually present upfront and have a strategy for each such sensitive information. This can be daunting especially if the dataset is enormous.
Challenges with Audio files
If you are training an audio model using audio files, you need to ensure the audio file has the sensitive information bleeped out. Bleeping too much can result in useful information being removed, while bleeping too little carries with it the risk of sensitive information being leaked. If you need to use audio files to develop a chatbot, you need to ensure the audio files are all transcribed and diarized before it is vectorized. The effectiveness of this is highly correlated with the audio quality.
Another consideration for audio files is to be wary of training the model on any individual's actual voice as is the recent case of OpenAI pulling its voice assistant Sky.
To prevent this, you need to ensure you are adding distortion to the audio in addition to de-identifying before you send it over for training any model.
Challenges with Text and PDF Files
For text files like logs, chat transcripts, etc you need to not only de-identify commonly used sensitive information like names, email but also custom entities. These could be elements like an internal project name or transaction ID.
PDFs can contain vector data (e.g : fonts) and raster data (e.g. images) and the quality of these can vary widely depending on how it was generated — it could be from a scan or could be natively generated. It can also contain non-textual data such as graphs and tables which would also contain sensitive data.
Challenges with Infrastructure
In addition to all these considerations, you should also be aware of the compute needed to de-identify these files. For example, a CPU instance might work well enough for a text file based de-identification, but audio fares very poorly on these instances and you need a GPU for this. Throughput considerations on how many words can be de-identified per second then becomes an important metric.
Industry Vertical Specific Challenges
There are also industry specific considerations, e.g: for healthcare data, information around dates, age, date of discharge, admission, etc are all sensitive information and need to be de-identified. The Health Insurance Portability and Accountability Act (HIPAA) mandates that any date that might be used to identify a person above 89 years old needs to be de-identified.
Once you have de-identified your data, you might also need to ensure this is certified by a third party agency that the dataset is indeed scrubbed of all sensitive data. The European Data Protection Board (EDPB) has specified that only certain approved bodies can certify data as being sufficiently de-identified.
This means that not just anyone can claim to certify General Data Protection Regulation (GDPR) compliance; it must be done by an approved certifying body. In contrast, HIPAA regulations in the United States allow for a more broader range of certifying parties.and has a more open certification process.
Given all this complexity, what do you do?
Learn how to protect sensitive data in AI applications. Download whitepaper →
How Can Skyflow Help with Data De-identification?
An effective way to de-identify large data sets is with a data privacy vault - a secure system for de-identifying sensitive data with robust access controls and governance policies. The de-identified data is then sent to the LLM for training, while the original sensitive data remains isolated and protected in the vault.
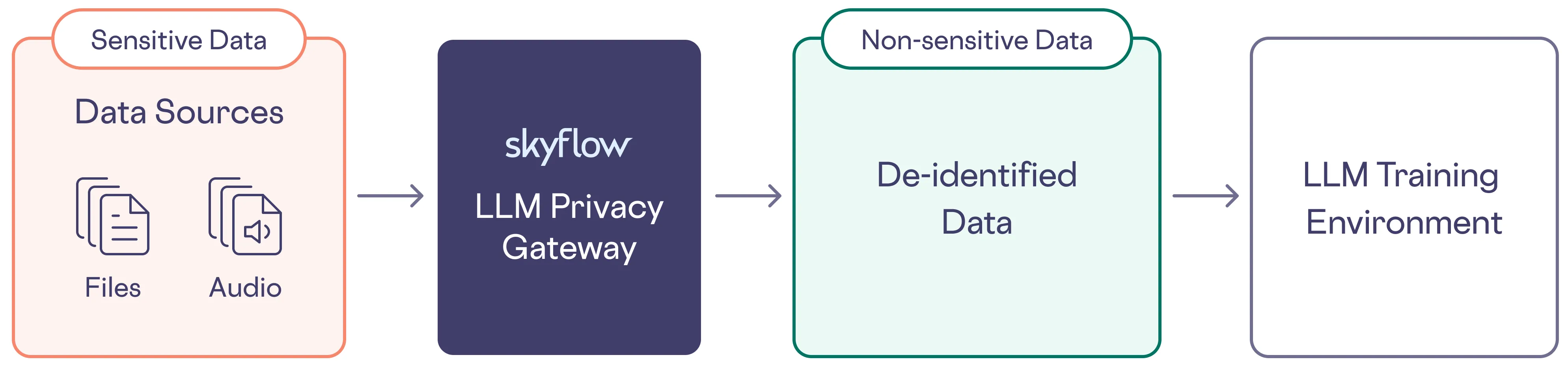
With the advanced capabilities of Skyflow Data Privacy Vault, you can run de-identify training pipelines across these large datasets in a secure and compliant environment.
Skyflow can handle the entire lifecycle of de-identifying these data sets, right from where we ingest this data (Skyflow or customer hosted SFTP/S3), de-identifying disparate data formats across audio, text, files, images and placing them back into a data repository (Skyflow or customer hosted SFTP) before it’s sent for training or fine tuning the model.
In addition, Skyflow also provides a rich set of features for every set of file types. For example, Skyflow lets you add custom pitch level or distortion to anonymize speakers or even sentiment analysis for building robust voice models. For dates, you can add custom date shifting to ensure dates are all offset by a random value.
Let’s look at a real world use case and how these features help deliver value to a leading healthcare company innovating in the LLM space.
How a Leading Healthcare Company is Building Privacy-safe LLMs with Skyflow
A leading provider of healthcare focused LLM solutions was building out a voice based assistant and a chatbot for patient facing healthcare tasks. This was based on a proprietary foundational model which was trained on real world data - audio calls between nurses and patients and doctors notes.
Since this was a model which was trained on 70-100B parameters, as expected the size of the data set was quite large, the customer had millions of audio and text files. All of these had sensitive information which needed to be de-identified and in some cases fully redacted before it was used for training. The audio files vary in duration, audio quality, had pauses, interruptions and background noises.
To effectively train the model on this large dataset, several requirements had to be met:
- Sensitive information in the audio recordings needed to be bleeped without losing any valuable contextual information.
- The audio pitch needed to be altered to change the voice.
- The audio conversation needed to be diarized. Diarization is the process of partitioning a speech into segments that correspond to different speakers.
- A call transcript along with redacted audio files needed to be available for training and we needed to ensure these are both in sync.
- A sentiment analysis score needed to be produced for the entire transcript.
- The transfer and processing of the sensitive files always had to be done securely via S3.
- In addition to the above, because the company is US-based, it was also crucial to validate that the generated de-identified data was certified by a third party certification agency to ensure HIPAA compliance.
Using Skyflow’s secure de-identification pipelines feature, the customer was able to offload all of these de-identification tasks to Skyflow.
The customer was able to ingest the files, pre-process the audio files, identify sensitive content and redact it. Additionally, Skyflow was able to provide them with de-identified audio recordings and also the certified diarized call transcripts.
Final Thoughts
In this article, we touched upon the importance of de-identifying sensitive data from your data sets before you use this to train your LLM. We followed that up with the slew of challenges that typically accompany these efforts, given the wide variety of data formats. We also presented some potential solutions on overcoming these challenges. However developing a holistic de-identification solution for all the various kinds of unstructured data takes away valuable time and resources from your team as you race to develop these AI enabled applications.
With Skyflow you get an out of the box solution to securely de-identify data across various form factors and do so securely via our APIs. In addition to this, we also provide attestation of the de-identified data. All of this is done in a secure and compliant environment which allows you to quickly reap the benefits of enabling new AI based applications without sacrificing data privacy.
For more information on how Skyflow can help you with your AI enabled applications, sign up for our Quick Start Environment here.