
Understanding AI & LLM Agents: Architecture, Security, & Deployment
We’ve all seen the videos of ai agents and LLM agents pulling real-time data, scheduling meetings, and automating simple tasks. LLM agents can interact across multiple systems, keep track of ongoing conversations, and handle complex tasks with minimal input from humans.
As CTOs and Engineering Leaders evaluate how to build and deploy AI and LLM agents inside their organizations, a healthy dose of skepticism will go a long way (show us a CTO who isn’t skeptical by nature).
The potential is massive, but so are the challenges – especially when it comes to managing sensitive data. LLM adoption requires pragmatic validation, proof-of-value demonstrations, and clear-eyed assessment of complexity and costs vs. benefit inside an organization.
So how are companies actually deploying ai and LLM agents inside their organizations and ensuring security and compliance of their data?
LLM Agents vs AI Agents: Are they actually different?
Technically speaking, LLM agents are a subcategory within AI agents. LLM agents are quickly deployable, have lower integration barriers, and excel in human interaction. They are exceptional at natural language reasoning and interaction, and can rapidly automate tasks involving natural language and knowledge work.
What makes LLM agents distinct from other forms of agentic AI is their foundation. They specifically use large language models as their "brain," providing:
- Natural language understanding for nuanced interpretation of requests
- Reasoning abilities derived from pre-training patterns
- Generalizability across domains without task-specific training
- Extensive pre-trained knowledge applicable to new situations
This language-centric approach gives LLM agents their distinctive capabilities, but AI agents more broadly may be required when the required tasks cannot be solved through language modeling alone (e.g., robotics, vision-based navigation, low-latency control tasks).
Learn how to protect sensitive data in AI applications. Download whitepaper →
What are LLM agents?
LLM agents combine large language models with tools, databases, and modules to tackle complex tasks with minimal human oversight. In other words, the LLM determines how the system behaves.
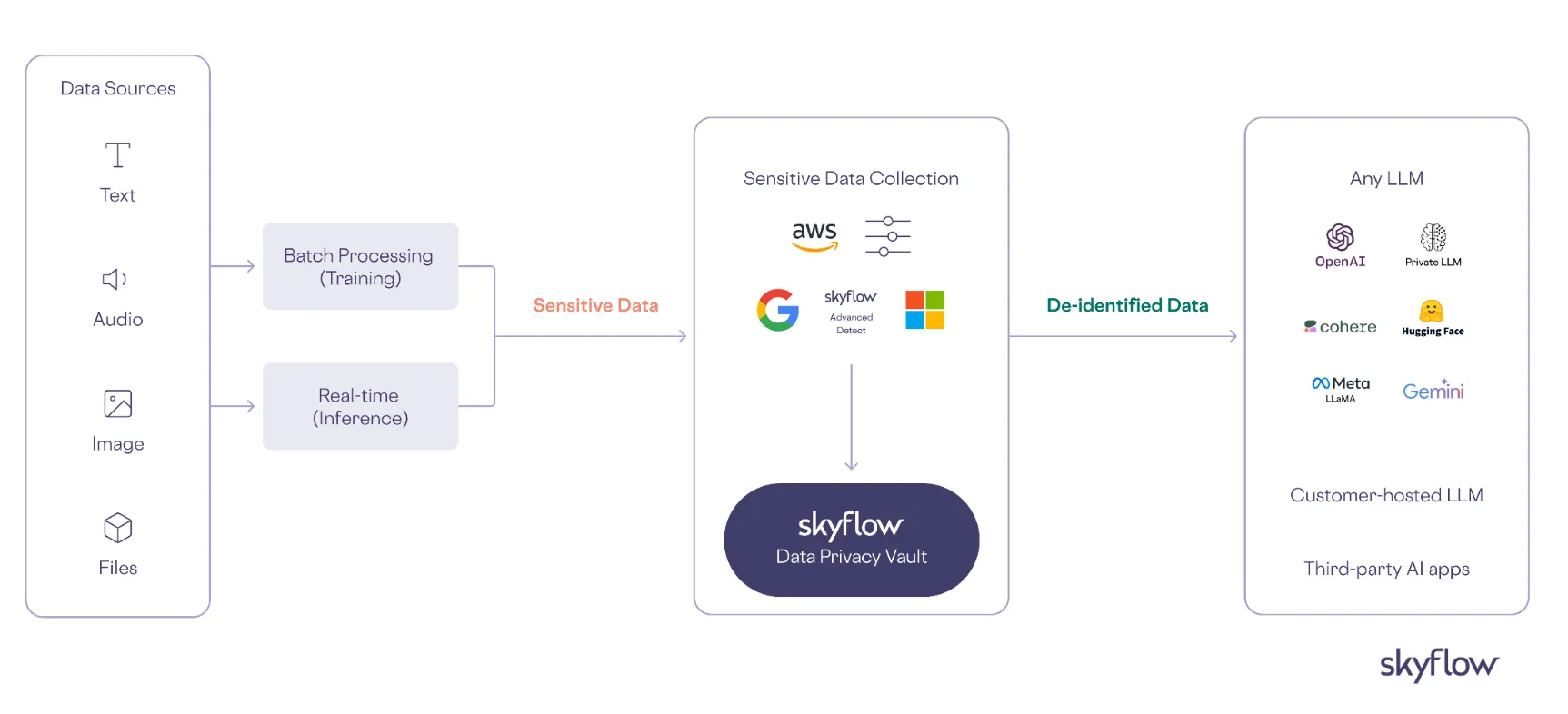
For example, imagine managing customer support for an e-commerce platform. A standard LLM like ChatGPT might help generate responses to customer queries, but it won’t interact with the inventory system to check stock levels or place orders. An LLM agent, on the other hand, could not only answer customer questions but also automatically retrieve up-to-date inventory data, place an order, and send a confirmation email – all without needing human intervention.
Unlike consumer-grade LLMs most of us have been working with, LLM agents do more than just generate text – they take action, interact with external systems, and maintain context while working toward specific goals.
This means they also may require access to sensitive data inside systems: things like customer records, personally identifiable information (names, addresses, phone numbers), payment information, and more.
>> Read More: How to build privacy-safe LLMs and AI agents
Types of LLM agents
LLM agents are commonly grouped by either their decision-making mechanisms or their architectural characteristics:
By Decision-Making Mechanism:
- Heuristic-Based Agents: Agents that follow predefined rules or heuristics or rules to decide on actions. Heuristics can sometimes appear more to be repackaged "rules engines" or decision trees with fancy labeling.
- Planning-Based Agents: Agents that use explicit planning or reasoning modules to determine their actions (e.g., ReAct (Reasoning + Acting), Tree-of-Thought (ToT), or chain-of-thought prompting (CoT)). These agents can significantly improve reasoning tasks by explicitly showing step-by-step logic. This transparency aids debuggability and explainability.
- Policy or Reinforcement Learning (RL)-Based Agents: Agents trained via reinforcement learning to select actions optimally. RL-based agents are sometimes accused of being overly complicated solutions looking for a problem, but they can genuinely excel in scenarios like recommendation systems and autonomous navigation. However, they’re notoriously difficult to deploy and require substantial resources. Our advice is to validate with clear business cases and demonstrable outcomes before making a heavy investment.
By System Architecture:
- Single-Model Agents & Multi-Component Agents: Some agents rely on a single, large model, while others orchestrate multiple specialized models (for planning, memory, or tool integration). Ironically, they both get dinged for the very nature of their architectures – single-model agents may be too simplistic, multi-component agents are too complex. In our opinion, prioritize simplicity unless the complexity adds general value.
- Tool-Using Agents: Agents designed to call external APIs, databases, or plug-ins as needed (e.g., “Toolformer” or “ChatGPT Plugins”). Tool integration can substantially enhance agent capability and practicality, but ensure each integration solves a genuine problem for your team or company. There is no shortage of AI hammers accusing business programs of looking like nails.
Understanding LLM agent architecture
Let's take a look at how LLM agents are built and the way they ingest and learn from data. Understanding the architecture can help when planning an implementation strategy.
The architecture consists of core structural components of the LLM agent which work inside a broader architecture:
Core Structure of an LLM Agent:
- The Agent Core/Brain functions as the central processor, using a language model to interpret requests, make decisions, and generate responses. This foundation determines your agent's ability to understand context and handle complex tasks.
- Planning modules break down complex tasks into manageable steps, evaluating approaches and implementing structured reasoning. Using feedback-based systems like ReAct, these modules adapt plans as new information becomes available – much like how we adjust our strategies during implementation projects.
- Memory systems maintain context through short-term memory (conversation tracking), long-term memory (information storage), and organized conceptual knowledge. These types of memory allow agents to build upon previous interactions and apply learned patterns to new situations, creating a more cohesive experience for users.
- Tool integration connects agents to external systems through APIs, databases, and specialized tools. By selecting and coordinating appropriate resources, your agents can access real-time data and expand their capabilities beyond the core language model.
- Interaction Layer (Human-Agent Interface): Defines how users interact with the agent (e.g., chat UI, voice interface, multimodal). The UX/UI significantly impacts perceived intelligence and usability of the agent.
- Monitoring, Observability, and Explainability: Infrastructure for tracking agent decisions, performance metrics, detecting bias/errors, and providing insights into why decisions were made.
- Safety, Security, and Compliance Modules: Guardrails, moderation tools to prevent harmful outputs, and data security and privacy vaults to manage sensitive data securely and enforce regulatory compliance (e.g., HIPAA, GDPR, DPDP, etc.).
- Learning and Improvement Loops (Feedback Systems): Mechanisms for agent improvement over time, either through reinforcement learning from human feedback (RLHF), Human-in-the-loop (HITL) systems, fine-tuning, or continuous retraining on new data. These help ensure agents remain effective and relevant in evolving business environments.
How AI and LLM agents work
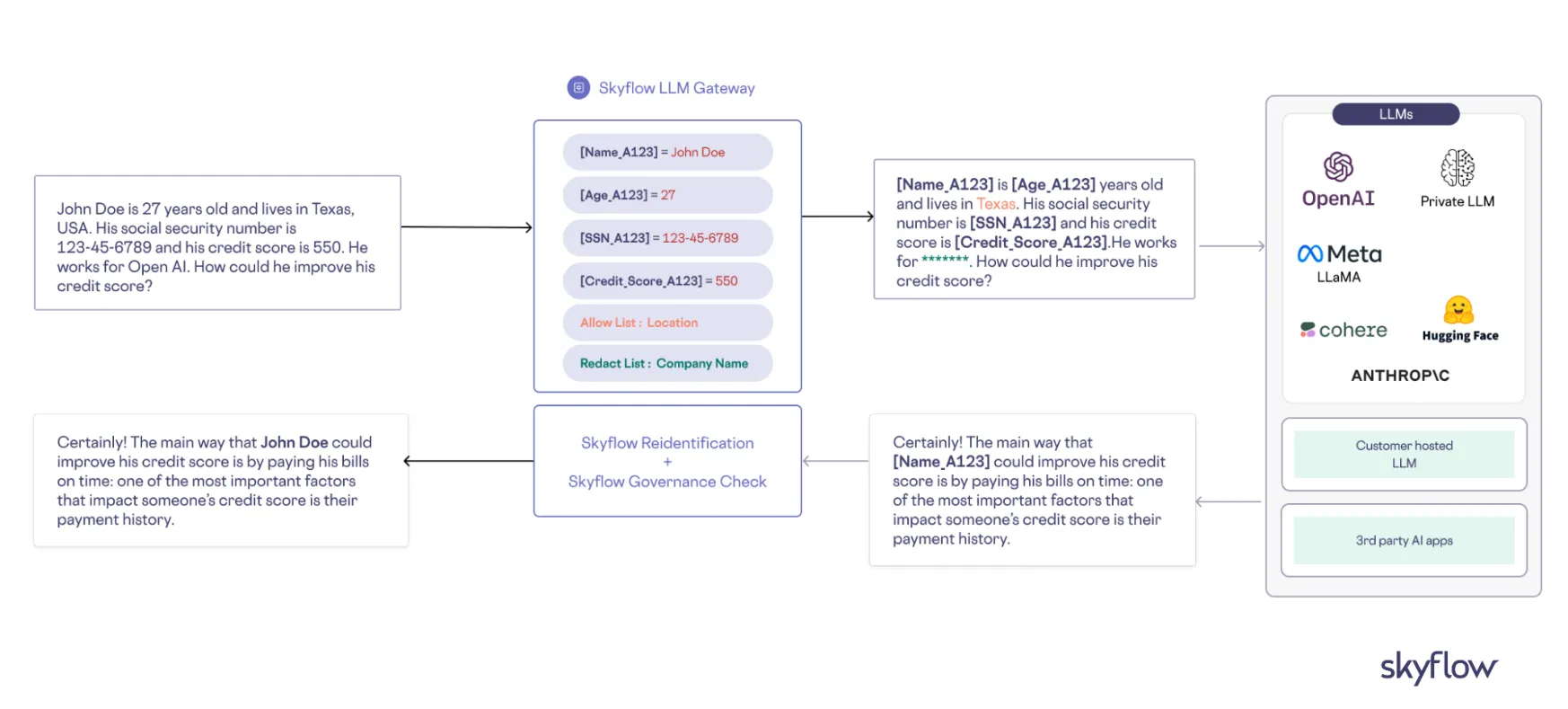
Let's walk through the operational workflow of LLM agents to understand how they process information and complete a wide range of specialized tasks.
1) Data ingestion and training process
Before deployment, LLM agents undergo extensive training and data preparation, beginning with base pre-training on massive datasets to develop a general understanding of language, followed by instruction tuning to refine the model's ability to follow directions.
Domain specialization enhances capabilities for specific industries, and Retrieval Augmented Generation (RAG) allows agents to access and incorporate real-time information from your company documents and knowledge bases, all while safeguarding sensitive data by avoiding exposure during pre-training. This is where we see data privacy challenges emerge – how do we give our agents the knowledge they need without compromising sensitive information?
Alignment techniques, such as reinforcement learning with human feedback (RLHF) ensure the agent behaves as intended. Additionally, continuous learning mechanisms enable the agent to adapt based on user feedback and performance data.
2) Input processing
When receiving a request, the agent analyzes the input by identifying core intent, extracting key entities, and checking memory for relevant context. It determines whether external tools are needed and begins forming an execution strategy.
For example, when handling a portfolio performance query, the agent identifies the relevant timeframes, determines the required financial data sources, and plans the necessary calculations – similar to how a financial analyst would approach the same question.
3) Planning and decision-making
During the planning phase, the LLM agent develops a structured approach (ReAct, ToT, etc.) by creating detailed execution plans and evaluating multiple potential methods. It determines what information is already available versus what needs to be retrieved, often breaking complex tasks into manageable subtasks with clear dependencies. This systematic planning ensures the task is completed efficiently and accurately. Error handling and recovery, including how the agent handles failures, retries API calls, or gracefully escalates problems to humans is typically addressed here.
4) Tool selection and execution
Based on the plan, the autonomous agent identifies the external systems and data sources it needs to interact with, handling authentication and authorization as needed. It communicates with external tool APIs, monitors for potential errors, and processes the returned data into formats suitable for further analysis or presentation.
This is another point where data security becomes essential. Agents need access to various systems and data, but that access must be tightly controlled and monitored to protect sensitive data.
>> Read More: The Rise of AI Agents: The Data Security Paradox
5) Response generation
After gathering and processing the necessary data, the agent synthesizes the information into a coherent response, formatted appropriately for the users' needs. It checks the response for completeness and accuracy before delivering it, often incorporating visualizations or structured data to enhance understanding.
6) Learning and adaptation
Advanced agents continuously improve through interaction, recording successful patterns by learning from user corrections and identifying recurring issues. These agents also adapt to individual user preferences and communication styles. This ongoing refinement helps maintain and enhance performance over time.
This process combines structured execution with adaptive learning, allowing agents to become increasingly effective at meeting user needs while operating within defined security and privacy constraints.
Now, let's walk through how to implement LLM-powered agents using an enterprise tech stack that prioritizes functionality and security.
Implementing enterprise LLM agents
Deploying autonomous agents in enterprise environments requires careful consideration of integration, governance, and security factors. Many organizations establish appropriate infrastructure and processes to help ensure these powerful tools deliver value without introducing risks.
Deployment considerations
Successful enterprise integration requires careful attention to connecting agents with your existing systems through external tool APIs, middleware, or custom connectors. The identity management system ensures agents can securely access only necessary systems and data, while infrastructure planning must account for compute resources, API throughput, and database capacity.
For example, a healthtech company might implement a data privacy vault to protect sensitive PHI in order to maintain HIPAA compliance, using tokenized data to enable secure access. This approach allows the company to maintain full functionality without exposing raw sensitive data.
>> Watch: How GoodRx protects sensitive user data with Skyflow
Data ingestion infrastructure
Secure data pipelines are needed for gathering and preprocessing training data and implementing PII de-identification processes. This includes automated sensitivity classification, compliance verification, and comprehensive audit trails.
For instance, a healthcare provider implementing an appointment scheduling system could use tokenized patient identifiers, enabling agent-assisted scheduling functionality without exposing actual medical details.
Performance optimization
Efficient operation relies on strategic implementation of caching for frequently accessed information and request batching to improve processing efficiency. Consider how a travel booking platform experiencing slow response times could optimize performance through edge-compliant vaults for regional speed and reduced tokenization operations.
Monitoring and maintenance
Real-time monitoring systems must track key metrics like response accuracy and latency. As an example, an e-commerce platform using LLM-based fraud detection would need to implement automated alerts for unusual API access patterns and potential data residency violations.
Governance and access controls
Organizations must prioritize establishing strict governance frameworks for LLM agents. For example, a customer service LLM agent for financial services would require:
- Fine-grained role-based access: Define clear permissions that determine which users and systems can interact with agents and what functions they can access.
- Data governance policies: Establish comprehensive rules governing how sensitive data is handled throughout the agent ecosystem.
- Approval workflows: Implement structured processes for reviewing and approving agent capabilities, especially when handling sensitive operations.
- Audit capabilities: Ensure comprehensive logging of all agent actions and data accesses to support compliance and security requirements.
- Accountability structures: Define clear ownership and responsibility for agent behavior, data handling, and ongoing improvement.
The key is to implement a multi-layered governance framework that provides appropriate access controls while maintaining detailed audit trails of all data interactions.
Success metrics
Defining clear performance indicators helps an organization evaluate LLM agent effectiveness:
- Task completion rate: Measure how often agents successfully fulfill user requests without human intervention.
- Accuracy metrics: Assess the correctness of information provided and actions taken.
- Response quality: Evaluate the relevance, coherence, and helpfulness of agent responses.
- User satisfaction: Gather feedback on how well the agent meets user expectations.
- Business impact: Measure tangible outcomes like cost savings, efficiency improvements, or revenue generation.
For example, a dating app with a chat moderation tool might evaluate it by measuring false positive and negative rates for inappropriate content detection, using these metrics to refine system effectiveness.
Regulatory compliance
Implementation must address a wide range of regulatory frameworks across industries and regions. Data residency and sovereignty regulations like GDPR, CCPA, and DPDP and industry-specific regulations like HIPAA all impose strict requirements. Organizations must also consider transparency requirements and cross-border data transfer restrictions in global deployments.
This brings us to perhaps the most critical aspect of enterprise LLM agent implementation: security and privacy considerations.
Learn how to protect sensitive data in AI applications. Download whitepaper →
Security and privacy considerations of LLM agents
As LLM agents become more integrated into enterprise systems, they introduce unique security and privacy challenges due to their access to sensitive data across multiple systems. Here are some of the main challenges that organizations need to safeguard against to get the maximum ROI from their AI investment:
Data Protection & Privacy Challenges:
LLM agents can inadvertently expose sensitive information through training data leakage, inference attacks, and unauthorized tool access. For instance, a healthtech company using LLM agents for patient support might be unknowingly trained on raw medical records. If a patient were to later query the system, the model could regurgitate actual patient data, violating HIPAA regulations and exposing protected health information.
Manipulation Risks
Agents are vulnerable to prompt injection, jailbreaking, and malicious tool manipulation that can compromise security. A financial services chatbot designed to help customers with account management could be manipulated by bad actors using carefully crafted prompts to bypass authentication checks and access sensitive account details.
System Integrity
In multi-agent systems, a compromised agent in one part of the system can spread misinformation or malicious content to other agents, causing security issues to cascade throughout the network. For example, if a travel booking platform relies on multiple agents for customer support, payment processing, and fraud detection, and the identity verification agent were to be compromised, it could feed falsified data to the other agents, leading to unauthorized transactions and fraudulent bookings.
Securing data for LLM agents
To address these challenges, enterprise organizations need to implement specialized data security infrastructure.
- De-identify sensitive data with a data privacy vault, isolating sensitive information from LLM agents while maintaining functionality. This approach uses advanced encryption and tokenization techniques to protect personally identifiable information (PII), payment data, and other sensitive information while still allowing agents to perform their intended functions.
- Automate detection and control systems that continuously monitor data flows, automatically identifying and redacting sensitive information before it reaches LLM agents. These systems enforce granular access controls and time-based permissions, ensuring agents can only access the minimum necessary data for their specialized tasks.
- Centralize governance and audit capabilities to provide comprehensive visibility into all agent-data interactions. This enables organizations to maintain detailed audit trails, simplify compliance with regulations like GDPR, CCPA, and HIPAA, and quickly identify and respond to potential security incidents.
- Implement input sanitization and prompt filtering to sanitize and validate user requests, detecting and blocking injection attempts. Use a layered approach of both regex-based rules and ML-based classifiers trained specifically on adversarial inputs.
- Separate authentication from chatbot logic by delegating all sensitive operations to isolated microservices that require explicit authentication tokens. Implement Least-Privilege Access Control to ensure the chatbot interacts with backend services using limited permissions, preventing broad access to sensitive data without explicit customer consent or validated session tokens.
- Use structured outputs or responses (e.g., JSON or standardized API responses) to limit chatbot outputs strictly to predefined data formats, reducing the risk of unintended sensitive data leaks. Enforce strict schema validations on responses to prevent injection via manipulated external tool outputs.
- Deploy continuous adversarial monitoring and alerting and automatically flag unusual access patterns or repeated authentication attempts. Anomaly-based monitoring systems designed specifically to detect unusual chatbot interactions can indicate prompt injection or jailbreaking attempts in real time.
- Ensure comprehensive logging of all chatbot interactions and decisions, establishing accountability and auditability, and regularly audit logs using automated security tools and human review to proactively identify and address potential vulnerabilities.
Implement these security measures as an integrated framework rather than isolated controls, creating multiple layers of protection that work together to secure enterprise AI agent ecosystems while maintaining the agents' utility and effectiveness.
Transform your enterprise with a secure LLM agent framework
As LLM agents become increasingly central to enterprise AI strategies, remember to balance innovation with security and privacy. Successful deployment hinges on understanding both thei technological capabilities and implementation considerations.
Want help building and deploying secure LLM agents? Book your demo today to speak to one of our experts about how Skyflow can help protect sensitive data while delivering powerful AI capabilities.