
What Is Sensitive Data Sprawl and How Can You Prevent It?
You open your business up to a whole host of risks, such as data breaches, financial loss, reputational harm, and compliance risks, when you store sensitive data across multiple locations.
To avoid these risks, your business needs a data privacy vault to store sensitive data. But before we get to the solution, let’s begin by exploring what sensitive data sprawl is and the business risks it poses.
What Is Sensitive Data Sprawl?
Sensitive data sprawl occurs when sensitive data is replicated as it’s copied and stored across various applications, databases, data pipelines, and logs — making it impossible to effectively govern access and increasing the work required to comply with data privacy laws and industry standards. For business, sensitive data generally refers to customer financial information such as payment card industry (PCI) and automated clearinghouse banking (ACH) data, personal healthcare information (PHI), and personally identifiable information (PII) like Social Security numbers.
You might store customer information in your customer relationship management (CRM) system, for example, which later gets replicated to your billing system, data warehouse, and analytics tools. You might also have sensitive customer data stored in a variety of SaaS apps, or employees who share sensitive data via unauthorized apps and store this data on their personal devices.
When you start investigating the extent of sensitive data sprawl in your systems, you’ll probably discover that sensitive data is present nearly everywhere, as shown below:
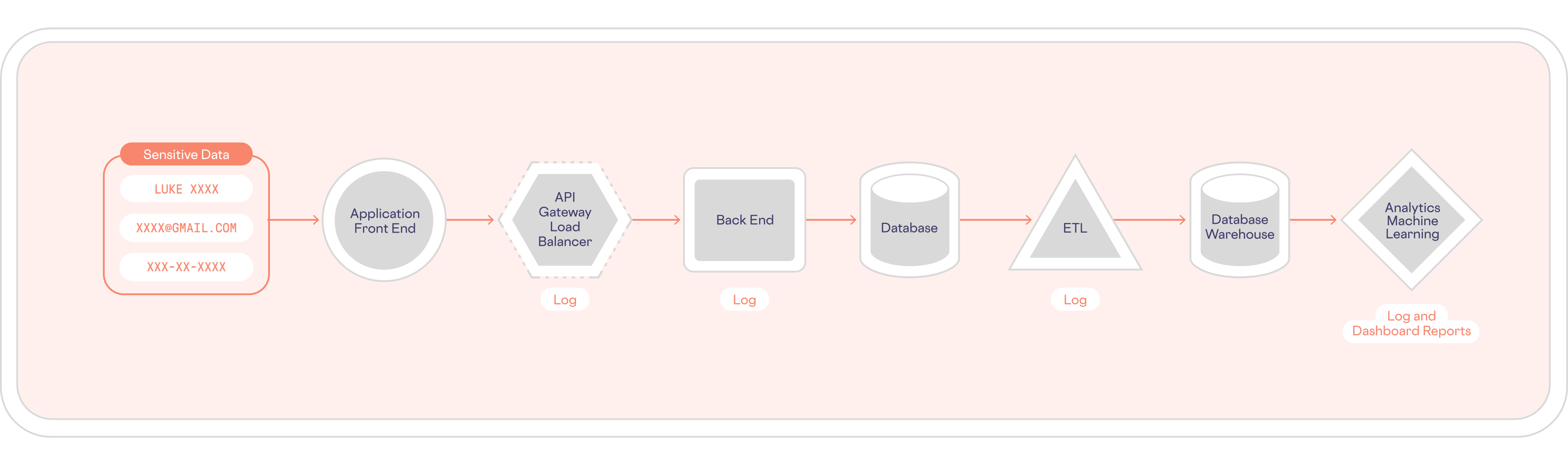
And, while you need to use this data for various critical business workflows, each sensitive data instance becomes an opportunity for cybercriminals to breach and misuse this data. And because you don’t know which sensitive data is stored in which systems, that unprotected data is even more likely to be misused.
With data sprawl, you lack sensitive data visibility.
The Business Risks of Sensitive Data Sprawl
Sensitive data sprawl undermines efforts to protect the privacy of sensitive data — exposing this data to breaches from bad actors who might misuse it for their own purposes. As a result, you risk millions of dollars in financial losses, missing key compliance requirements, and potentially suffering irrecoverable reputational harm.
Data breaches cause both direct and direct financial losses and reputational harm. And, sensitive data sprawl also increases the scope of compliance and complicates data residency.
Financial Losses
IBM’s Cost of a data breach 2022 report states that US companies incur an average of $9.44 million in financial losses per data breach. Furthermore, it takes about nine months on average to identify and contain a data breach.
Because sensitive data sprawl makes it harder to identify breaches, it not only makes it easier for data breaches to occur, it also further delays the containment of breaches.
Reputational Harm
A data breach impairs your ability to regain the trust of existing customers. The mistrust and bad PR around your business also significantly lower your ability to attract new customers.
Depending on how cybercriminals misuse your customers’ personal information, you risk not being able to regain their trust ever again.
Compliance Challenges
Sensitive data sprawl makes it harder to achieve compliance. For example, a PCI compliance assessment will take into account all the systems that store or process PCI data. So, the larger your PCI data footprint, the larger your compliance scope, and the more complicated and drawn out the assessment becomes.
Data sprawl creates an expensive and time-consuming investigation when you need to find all of the data that falls under the scope of compliance to complete a PCI compliance assessment or verify compliance with HIPAA.
Data Residency Complications
Data residency requirements and data protection laws restrict where sensitive data can be stored. For example, the healthcare data of Australian residents is legally required to remain within Australian borders.
Similarly, there are complex requirements under GDPR that restrict where sensitive data can be stored. But uncertainties around GDPR restrictions have driven companies like TikTok to geo-duplicate their entire backend in the EU.
Sensitive data sprawl makes it difficult to honor data residency requirements because when this data is present everywhere in your systems, you can’t use a cost-effective approach to data residency. Instead, you have no choice but to geo-duplicate your backend to remain compliant across markets.
Poor Data Quality
Because sensitive data sprawl creates many instances of sensitive data, it hinders your ability to answer questions like “how many active customers do we have today?” with any degree of confidence.
Not having a single source of truth to help you understand your customers can lead to poor business decisions and lost opportunities.
How to Prevent Sensitive Data Sprawl and Ease Compliance
To prevent data sprawl and ease compliance, you should start by identifying your most sensitive data and planning your approach to data governance. Then, you should isolate your sensitive data in a zero trust data privacy vault where you can implement centralized data governance with fine-grained access controls.
1) Data Mapping: Locate and Categorize Sensitive Data
Instituting sweeping changes across all your sensitive data in a few days might break existing workflows that are essential to the health of your business. So, cleaning up data sprawl is a process that requires some planning.
The first step is to categorize sensitive data into three tiers based on urgency, regulations, and risks, and note where this data is stored as you categorize it.
We recommend categorizing sensitive data into the following three tiers:
- Tier 1: Highly regulated data that carries high risk and needs urgent action: Sensitive data that has the highest risks and data that are subject to Federal Trade Commission enforcement and compliance requirements falls into this first, most important, tier. This includes sensitive data that is subject to regulations like CPRA and GDPR, or industry standards like PCI DSS.
- Tier 2: Less regulated data that’s still high risk: Sensitive data that carries significant business risks but that is less regulated falls into this second tier. A good example of sensitive data that falls into this category is customer banking data (or ACH data) which is highly sensitive, but not as tightly regulated as PHI or PCI data.
- Tier 3: Unregulated data that has the lowest urgency and risks: Lastly, your remaining sensitive data falls into this category. You can follow up to better protect this data after addressing the first two tiers described above.
When you’re done categorizing your sensitive data and determining where it’s located, you’re likely to be alarmed by how many places your sensitive data is duplicated, and how many systems could grant access to it.
Now that you’ve categorized your sensitive data, it’s time to define your approach to data governance.
2) Define Data Governance Needs
Next, you should define how you want to approach data governance for each sensitive data tier. First, identify which users and services need to execute which workflows, and what level of sensitive data access they require. This analysis will help you later, after you isolate sensitive data so you can configure global data governance policies.
You should define your approach to data governance after factoring in your unique business and compliance needs. For instance, if your business needs to integrate with Visa and Mastercard for payments, then your data governance processes should address how to securely handle sensitive PCI data.
But, designing your approach to sensitive data governance is different than addressing sensitive data sprawl to make effective data governance achievable. That’s because as long as sensitive data is scattered across your backend, application database, logs, and analytics systems you don’t have a comprehensive way to manage sensitive data access.
You can try to govern the sensitive data stored in each of these locations with built-in access controls, or by using point solutions, but this approach has significant drawbacks. Governing sensitive data access without first addressing data sprawl is error prone and carries a high maintenance burden because you’ll have to interact with many different systems to update access control policies, fragmenting your approach to data governance.
To turn your data governance guidelines into effective data governance policies, you first need to isolate sensitive data in a single location where you can govern it with fine-grained access controls. You can’t solve data sprawl or data governance headaches without first isolating sensitive data.
3) Isolate Sensitive Data and Implement Data Governance
You can address your business needs and ease any compliance requirements by isolating all of your sensitive data in a data privacy vault. A data privacy vault isolates, protects, and governs access to sensitive data so that employees and workflows get access to only the data that they need, and nothing more. And, it gives you a centralized place to turn your data governance guidelines into effective, maintainable access control policies that go beyond what’s available in a data warehouse or database.
Skyflow Data Privacy Vault lets you solve the problem of data sprawl, updating the architecture shown above to one where sensitive data is isolated, protected, and governed in a vault, as shown below:
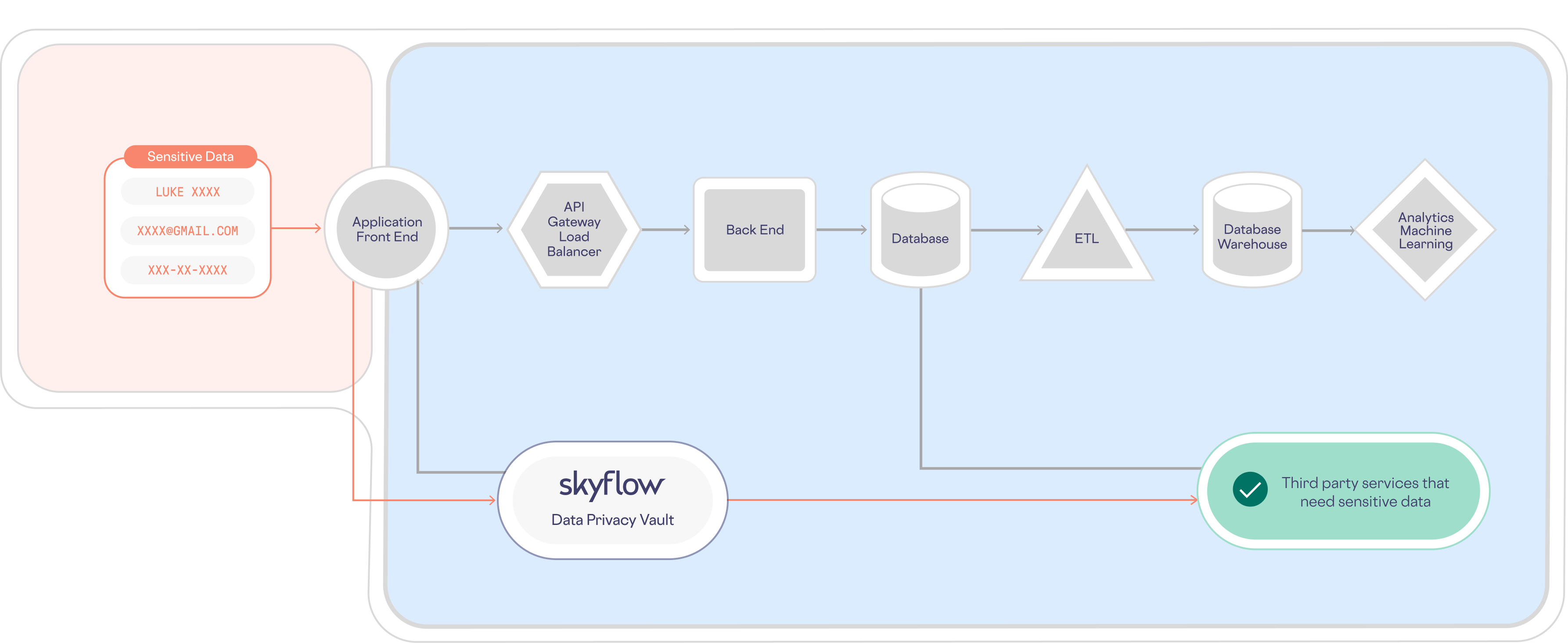
Safeguard Sensitive Business Data with Skyflow
As you can see, there are several benefits to avoiding data sprawl by isolating and protecting your sensitive data using Skyflow Data Privacy Vault.
Using Skyflow Vault significantly reduces the engineering effort that’s otherwise required to secure and monitor sensitive data. And, because Skyflow Vault isolates sensitive data, it eases compliance with CCPA, GDPR, PCI, SOC2, and more.