Securing Sensitive Data: Why Encryption Isn’t Enough
Engineering teams have the difficult task of figuring out how to maintain and securely store and manage use of personally identifiable information (PII). The magnitude of this need often depends on the sensitivity of the data collected, new and changing privacy regulations, and security incidents such as data breaches.
A natural place to start is encryption. If you want data security, surely encryption has to be part of your solution? But if you’re encrypting data, then you need to figure out your encryption key management approach. What do you use as a key? How are you rotating the keys? Do you go with a vendor for key management or build your own key management service?
Quickly you find out that encryption breaks operations like search and even exact match lookups. How can you look up PII without doing a full table scan? These complexities often require a dedicated team, diverting resources from core product development. This results in duplicated, inconsistent projects across different teams, detracting from your primary focus: delighting users and solving business problems. Also, since this is perhaps not your core competency, are you sure what you’re building is actually the optimal solution? And will it remain so over time?
In this article, we explore the common thought processes and engineering patterns we’ve seen in DIY data security. Then, we introduce an alternative: a fully managed data privacy vault that lets you concentrate on your product instead of your PII problems.
Learn how to isolate and secure sensitive data with a vault. Get your guide →
Starting with the End Goal
Most people tend to grossly underestimate what’s actually needed to solve their PII problems. You may think you only need encryption or masking, but in reality the list of things you need grows and grows to address all the business use cases for PII. The consequences of a mistake can be devastating (e.g. see the Evolve Bank data breach).
We’ll take you through why and how this happens, but before we get there, here’s the abbreviated list of things we believe you’ll end up having to build and maintain to address your PII problems from an architecture perspective:
- Encryption
- Encryption key management and rotation
- Encrypted search
- Data masking
- Role-based access control
- Fine-grained access control
- Secure file management
- Secure data sharing for calling APIs
- Auditing and logs
- Security operations
- Global deployment with the ability to shard customers by region
- Data deletion
- Compliance
Let’s take a look at why encryption alone isn’t enough.
The Journey Begins with Encryption
If you’re storing sensitive customer data, which most of us are, then you need to protect it. This isn’t simply the best way to treat your customers’ data – you are required to do it if your data fall under certain regulations like PCI DSS, HIPAA, GDPR, and others.
Encryption serves as a first line of defense, transforming readable text into unreadable ciphertext that can only be deciphered with a unique key. By encrypting PII, you significantly reduce your risk of unauthorized access and of a data breach.
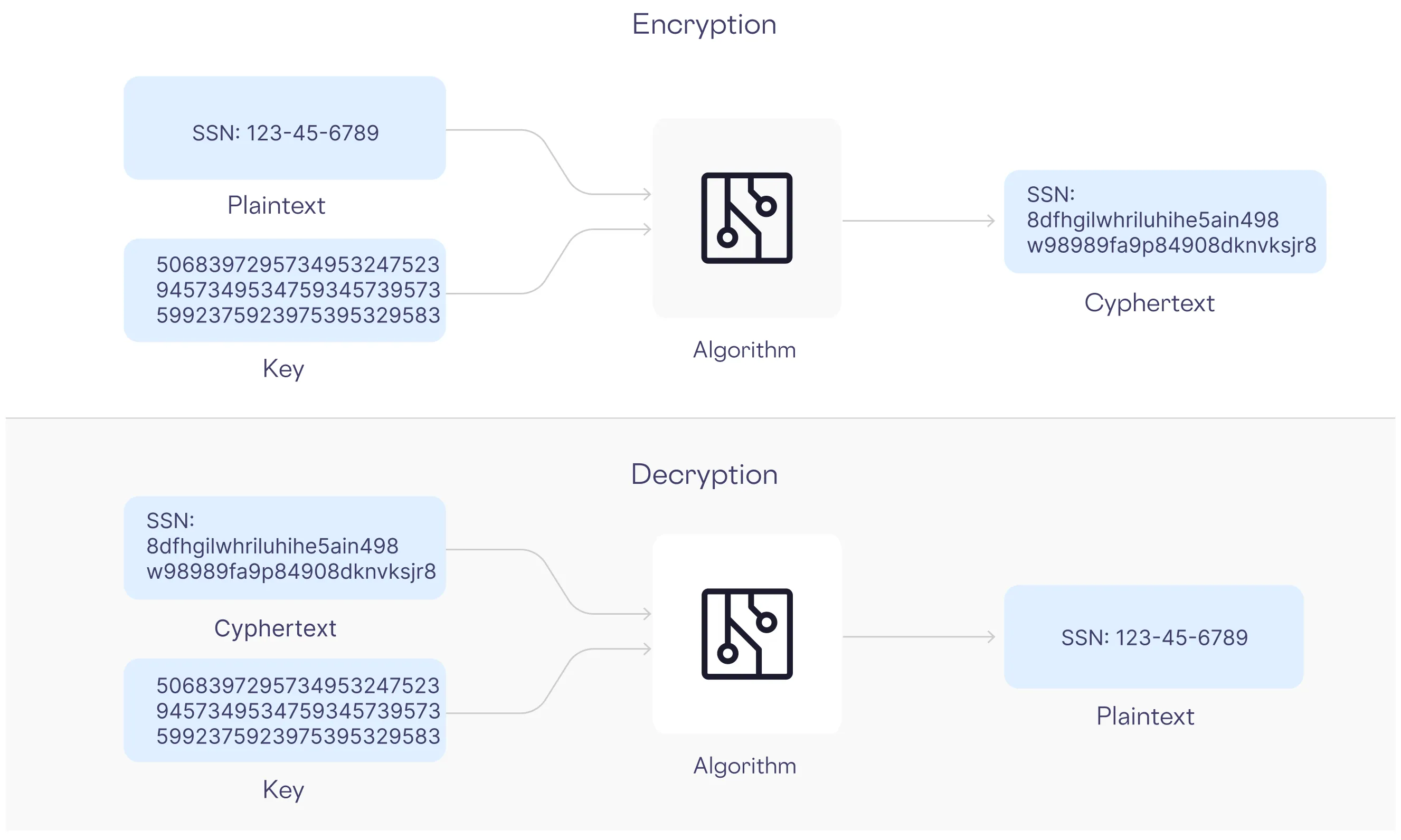
However, doing encryption right comes with a cost.
Besides choosing the correct encryption algorithm, all encryption algorithms and dependencies need to be continuously updated to keep on top of the industry best practices and latest knowledge. Encryption relies heavily on a key that needs to be stored somewhere. Using the same key for a prolonged period of time can potentially reveal information about the underlying key or even the data you’re trying to keep hidden. If your key is compromised, the fact that you’re doing encryption is moot.
There are hard choices you need to make along the way about what to encrypt. Do you encrypt the entire table and call it a day, or do you use different encryption keys for each column or even each field?
You can improve security by using different keys for different forms of data, but there’s more to manage and keep track of. Regardless of the choice you make, you’ll need a reliable Key Management System (KMS) to secure, use, and map the keys.
Securing the Key
To secure your encryption keys properly, you need to support the full key management lifecycle:

Each step has specific requirements and considerations that you need to think through, which are detailed here. You or your team has to decide how encryption keys are generated taking care to make the keys sufficiently long. You’ll need to maintain the mapping between the key and the data that it protects, store the keys, limiting access and use.
Security best practices state that encryption keys should be rotated every 12 months and PCI-DSS, HIPAA, and GDPR. Additionally, some regulations have specific requirements for key management and rotation, which you may need to build for. There are various approaches to key rotation like dual keying, staggered rotation, and atomic key updates. You need to decide which one to use and what happens if there’s any kind of network outage during a rotation.
Once you’ve worked through all of this, you have to consider what happens to the various copies of your encrypted data when you rotate your keys? These might be in read replicas, an analytics store, search database, and all the backups of these systems.
When you rotate your key, you don’t want to be locked out of the data in your backups, which means you need to backup the keys as well.
Are you backing up the keys securely using hardware security modules (HSMs) or other secure storage solutions? The backup keys also need to be encrypted and stored in a separate location to reduce the risk of being compromised. And what is your key recovery process in case the primary key is lost or compromised?
If you don’t think any of this can happen to you, see Co-founder and CTO of Paypal, Max Levchin’s post about nearly locking Paypal out of all of their customer’s 100+ million credit card and bank account numbers.
Encryption is Working but the Performance is Unacceptable
You and your team have worked through all the encryption idiosyncrasies, PII is secure, and you're feeling good. However, prior to shipping, during performance testing you realize every database interaction is excessively slow. All your well crafted database indices for fast lookups no longer work.
If we use envelope encryption where a data encryption key (DEK) is used to encrypt the actual PII data, and then the DEK itself is encrypted with a separate key encryption key (KEK), then each user insert operation looks as follows.
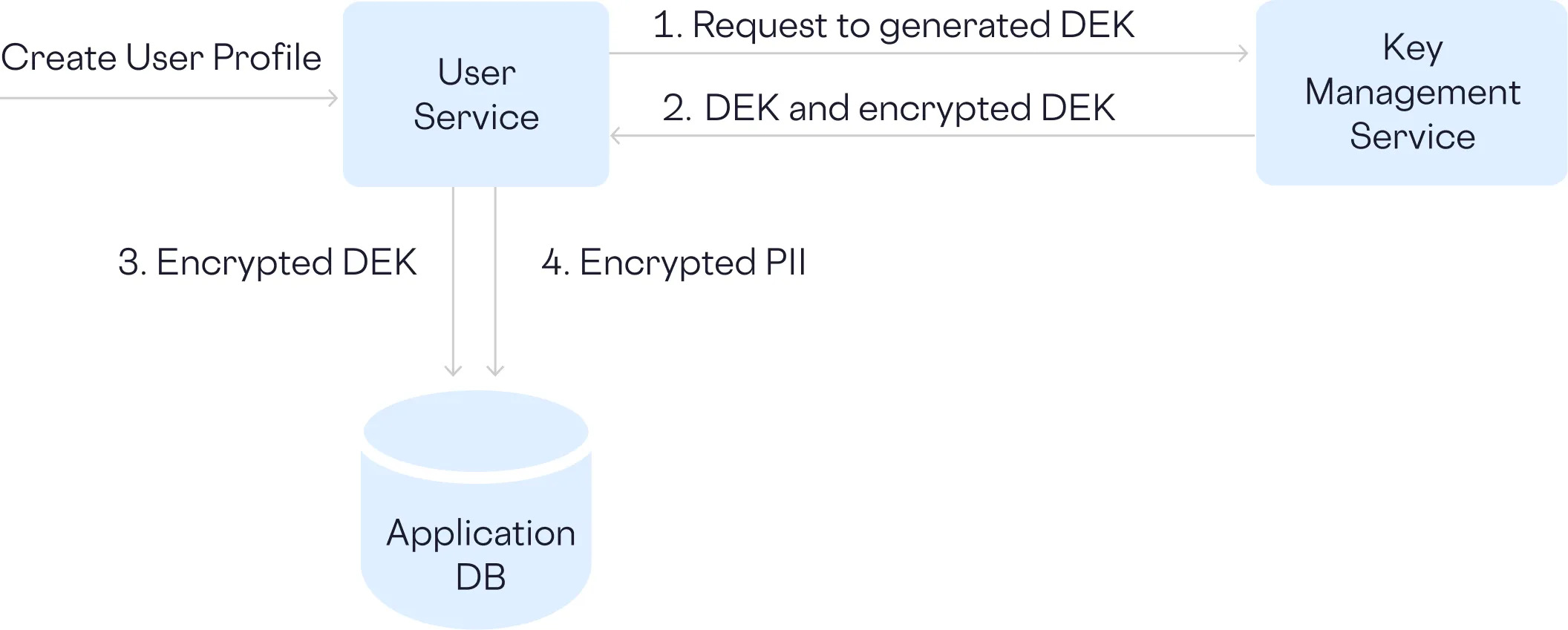
While this approach improved security, every lookup requires you to decrypt the data and do a full table scan. Also, every insert, update, and read operation now requires a trip to the KMS and a decryption operation, which is adding unacceptable latency.
So what are your options?
Optimizing KMS Interactions
If fetching keys from the KMS and records from the database is expensive in terms of money and latency, then it makes sense to introduce a cache. In this scenario, you first check the cache for the encryption key, if it’s there, great, if there’s a cache miss, then you’ll retrieve it from the KMS and update the cache.
Because you’re now relying on a cache for quick access to encryption keys, you’ll need a job to manage the cache to remove unused keys and also force a refresh whenever your encryption keys rotate. Tricky issues but not insurmountable.
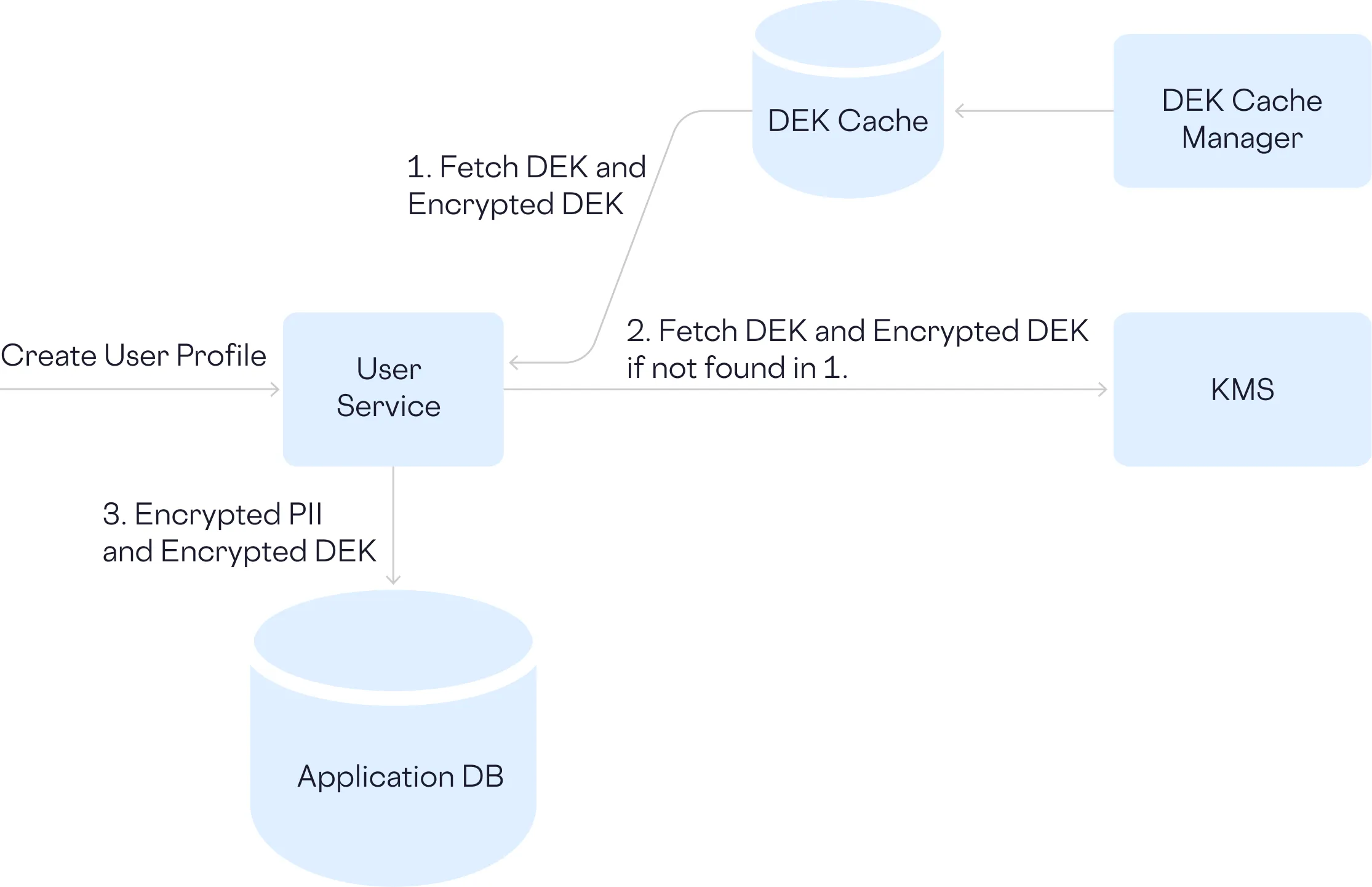
Optimizing the Database Interactions
The cache works great for reducing your KMS call cost, but you haven’t solved your database index problem yet. You could cache the decrypted PII, but that defeats the purpose of using encryption in the first place. Alternatively, you could cache the encrypted PII so you don’t always need to go back to the database if you know the record you need to retrieve.
However, cache invalidations and refreshes get more complicated here because you’re going to be adding and updating customer information on a regular basis in comparison to your encryption keys. Once you’ve worked through those details, you still need a way to look up PII quickly without the cost of decrypting the data for performing comparisons.
To address this issue, along with storing encrypted PII, you can introduce a search database like Elasticsearch that contains hashed PII values. You have to work through potential collisions and the deterministic nature of hashing might not be secure enough depending on the type of data you’re storing, but what choice do you have?
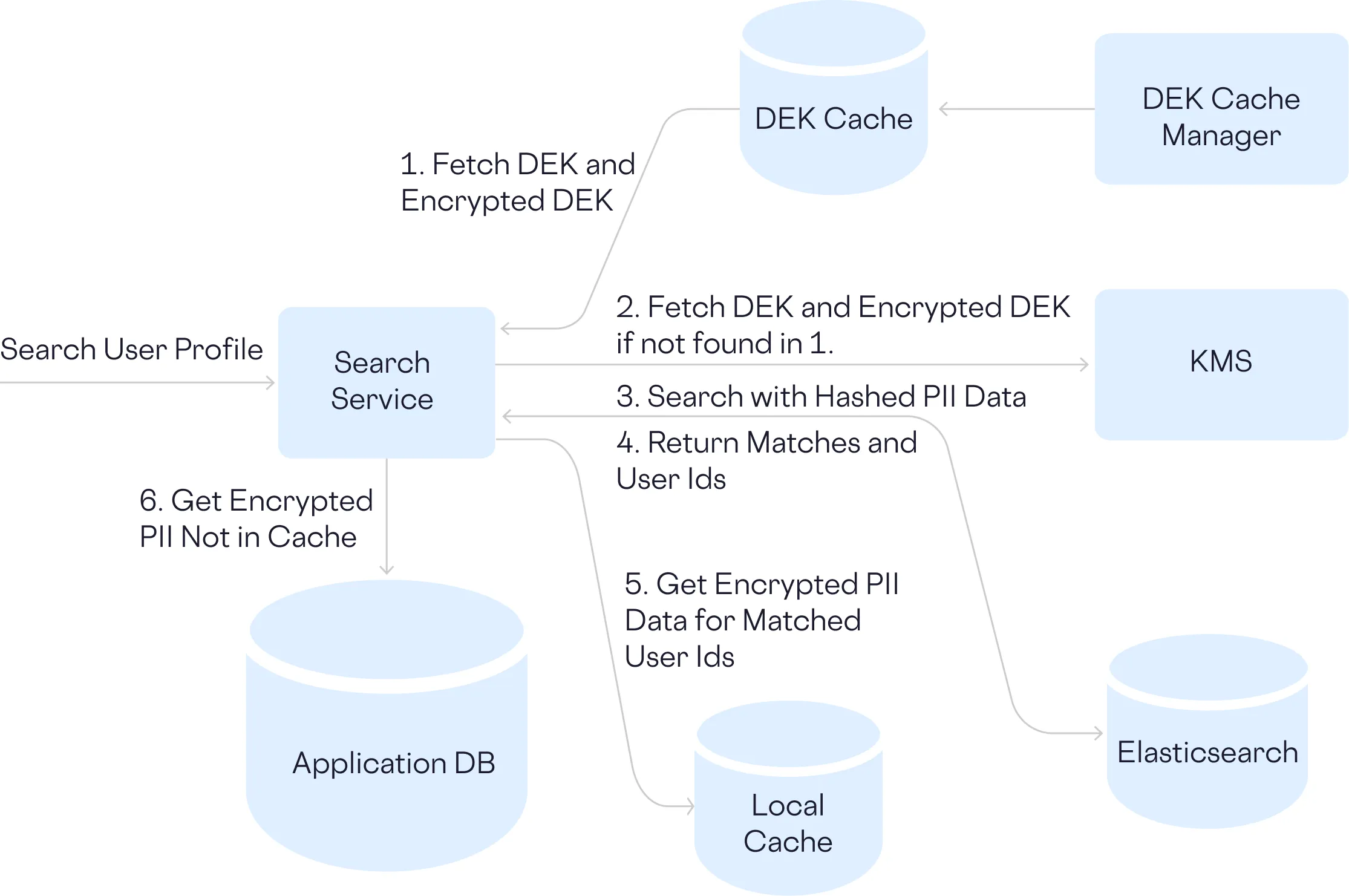
Encrypted PII and your DEKs are mostly retrieved from the cache and PII lookups happen against hashed data.
Oh No, You Broke Search
Hashing works great when you’re doing an exact match lookup but for search to work properly, you need to be able to maintain the original expected order of the PII values and for things like a name search, you need substring matches.
To support substring matches, you may need to break up the original text and store smaller units as a series of n-grams with a rolling hashing or implement something like the Rabin-Karp Algorithm. To preserve order, you can introduce an original order field to maintain the plaintext PII data’s original sequence.
You’re now managing many different systems that all need to work together. It's much more complicated, but you mostly avoid working directly with unencrypted PII.
Learn how to isolate and secure sensitive data with a vault. Get your guide →
Data Masking and Access Control
Everything is working great, but you also need to make sure customer support only sees the last four digits of a customer’s phone number and that your marketing team needs to know a customer’s birth month but not how old they are.
Now you’re faced with adding support for dynamic masking depending on the user’s role. Ideally you also log every access to PII so you know if someone is doing something that they shouldn’t be doing with it. This is also required under certain privacy regulations. And if your customer support team should only have access to some customer records and some fields, how are you going to provide that access and only that access?
Additionally the CEO wants to know what you’re doing in the generative AI space, so now you need to figure out how to train a LLM without leaking sensitive customer data.
What originally seemed like a straightforward matter of encryption has ballooned into a multi-person team and large scale project with a lifetime of maintenance.
For an industry reference, see this story by Shopify about their three year journey to solving this problem. GoodRx spent 10 months with 8 engineers on this problem before giving up, see their CTO speak about it here.
At this point, you might be starting to wonder, should I really be spending my time on this or customer-facing features that drive revenue?
We haven’t even discussed the other pieces that will come along with maintaining this infrastructure and making sure it’s secure like:
- Threat detection
- Software patches
- Auditing and logs
- Policy based access control
- Employee training
A Practical Alternative to DIY Data Privacy
Beyond the preliminary cost of building something in-house, along with the maintenance, the other thing to consider is the consequence of doing it wrong. When it comes to data security, you can’t afford to not do it right.
If we zoom out for a moment and look at the landscape of data breaches, there have been more data breaches in 2024 than any other year in history, and at the time of this writing, we’re only halfway through the year. This is despite companies allocating large amounts of money and effort to cybersecurity. This is a massive problem.
However, there are companies like Apple, Google, Netflix, and a handful of others that arguably have more customer PII than any other company on the planet that aren’t part of the data breach headlines. So what is it that these companies do that protect themselves?
Each of these companies have independently followed a similar architectural pattern for PII.
They isolate the PII separate from their existing systems, where they protect it, and control access. This effectively de-risks their existing application and analytical systems from potentially leaking PII because the PII doesn’t exist in any of those layers.
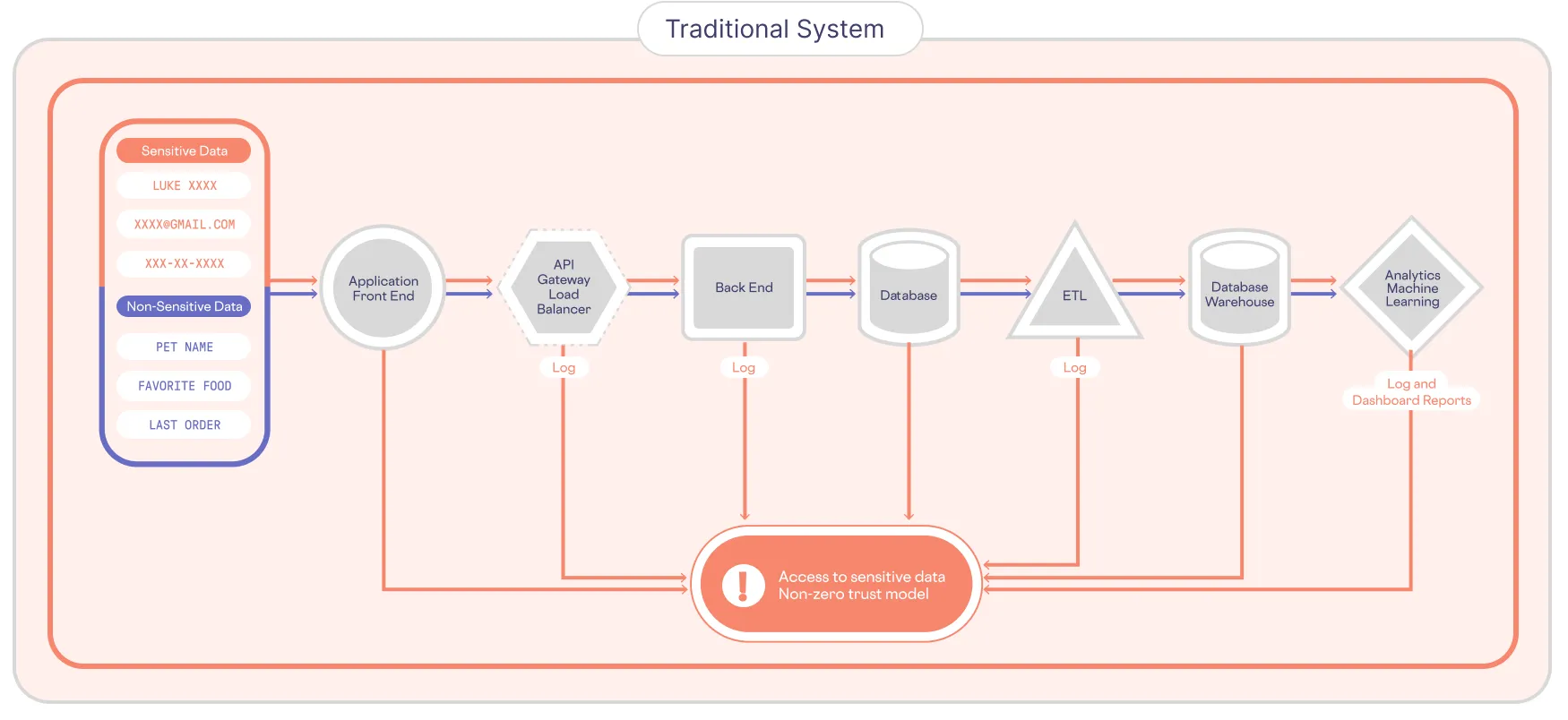
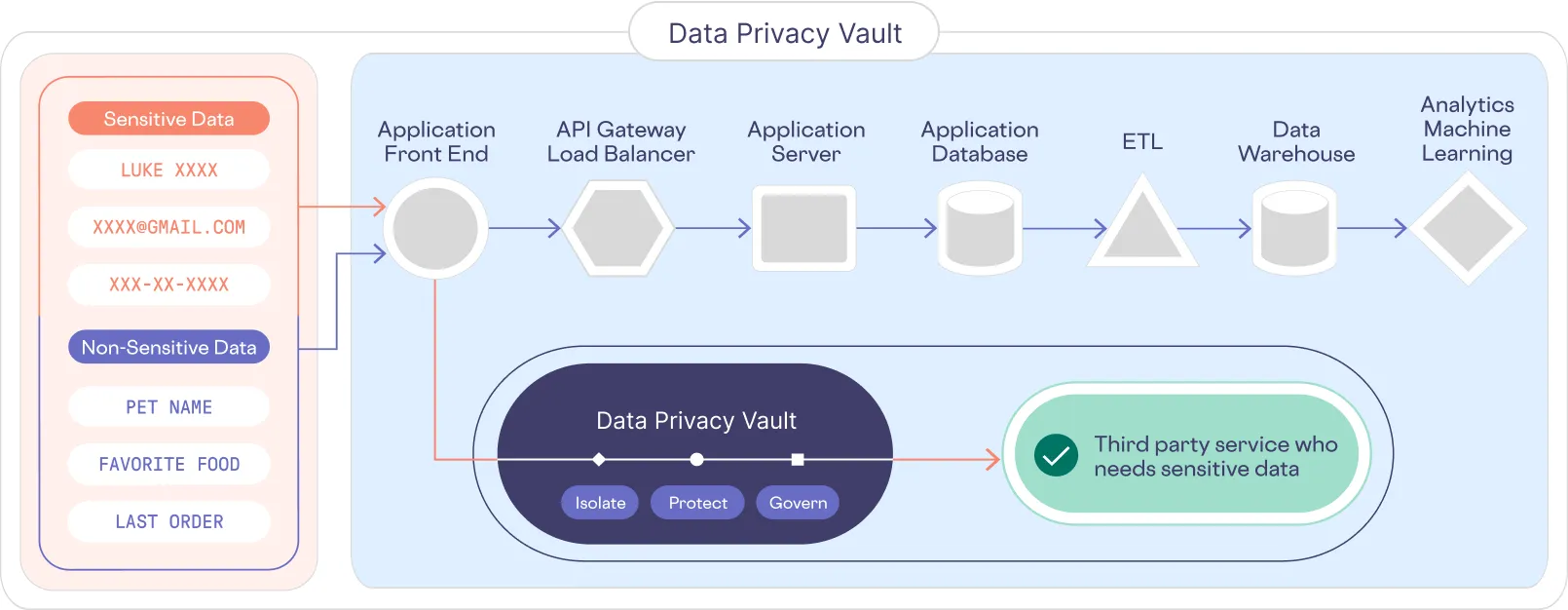
At Skyflow we’ve taken this best in class approach to PII data protection and made it available as a service. To solve the problem of keeping data secure while usable, we developed proprietary technology known as polymorphic encryption.
And then added support for:
- Governance
- Data residency
- Secure cloud functions
- Pre-built third-party integrations
- Data masking
- Data sharing
- Multiple deployment models
- BYOC, BYOK, and BYOT
Check out GoodRx’s CTO, Nitin Shingate, speaking about how they use Skyflow in this fireside chat.
If this sounds interesting, let’s talk. You can contact us here.