The Data Cloud’s Cheese and Diamond Problem
In an era where data breaches make headlines weekly, even top companies with massive cybersecurity investments struggle to protect sensitive information like social security numbers. The root of this problem lies in a decades-old misconception about how we treat PII.
In any given week, if you search the news for “data breach”, you’ll see headlines like the ones below.

Companies like MGM and Caesars spend millions of dollars on firewalls, SIEMs, HSMs, and a whole smorgasbord of cybersecurity tools and yet, they can’t protect your social security number.
From hotels and casinos to some of the most innovative technology companies in the world, why is it that companies with seemingly endless financial and talent resources can’t get a handle on their data security challenges?
I believe this is due to a fundamental misunderstanding about the nature of data that started over 40 years ago.
Back in the 1980s, as computers found their way more and more into businesses, we lived in a disconnected world. To steal someone’s data, you had to physically steal the box the data lived on. As a consequence, we assumed that all data is created equal, that all data is simply ones and zeros, but this is wrong. All data isn’t created equal, some data is special, and needs to be treated that way.
In this blog post, I share my thoughts on what I refer to as the “Cheese and Diamond Problem” and how this has led to the data security challenges companies face today. I also explore an alternative approach, a new way of thinking, a privacy by engineering approach that helps us move towards a world where security is the default, and not bolted on.
The Cheese and Diamond Problem
Imagine that in my house I have cheese and I have diamonds. As a gracious host, I want guests of my home to be able to access my cheese. They should be able to freely go into the refrigerator and help themselves to some delicious cheese and perhaps a cracker.
However, I don’t want just anyone to touch my diamonds. Perhaps my diamonds even have sentimental value because it’s a diamond ring that’s been passed down through many generations in my family. Clearly the diamond is special.
Yet, if I store my diamonds in the refrigerator next to my cheese, it makes controlling access to the diamonds much more challenging. By co-locating these very different objects, my refrigerator alone isn’t enough to make sure my wife has access to the diamonds and cheese, but my guests only have access to my cheese.
The rules of engagement for something like diamonds are completely different than the rules of engagement for cheese. We all understand this distinction when it comes to physical objects.
This is exactly why my passport and my children’s birth certificates aren’t in the junk drawer in my kitchen with my batteries and my flashlights. If someone breaks into my home and steals my batteries, it's not that big a deal, but if someone steals my daughter’s birth certificate, then I not only feel like I’ve failed as a parent, but the information on her birth certificate is also now compromised forever. I can’t simply replace her date of birth.
Despite all of us intuitively understanding that some physical objects are different, that they’re special, we somehow miss this point when we work with data. We don’t apply this thinking to Personally Identifiable Information (PII). We treat it like any other form of transactional or application data. We stuff it in a database, pass it around, make a million copies, and this leads to a whole host of problems.
The PII Replication Problem
Let’s consider a simple example.
In the diagram below, which represents an abstraction of a modern system, a phone number is being collected in the front end of the application, perhaps during account creation. That phone number ends up being passed downstream through each node and edge of the graph and at each node, we potentially end up with a copy of the phone number.
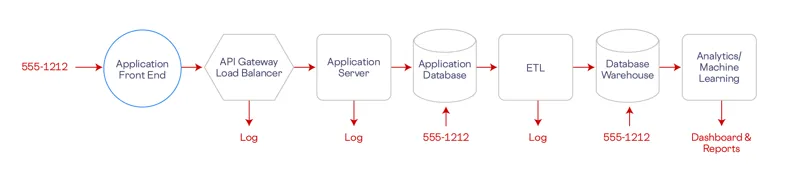
The PII replication problem.
We store it in our database, in the warehouse, but we may also end up with a copy in our log files and the backups of all these systems. Instead of just having one copy of the phone number, we now have many copies and we need to protect all those locations and control access consistently wherever the data is stored.
Imagine that instead of having one copy of your passport that you keep in a secure location, you made 10,000 copies and then distributed them all over the world. Suddenly keeping your passport safe becomes a much harder problem in all 10,000 locations than if you have one copy secure in your home.
But this is exactly what we do with data.
We copy it everywhere and then attempt to lock down the hatches across all these systems and keep the policies and controls in sync about who can see what, when, and where. Additionally, because of the Cheese and Diamond Problem, we can’t adequately govern access to the data because the intermixing of our data conflates the rules of engagement about who has access. This quickly becomes an intractable problem because businesses don’t know what they’re storing or where it is, leading to the world we live in now where major corporations have data breaches on a regular basis.
Not All Data is Equal
Businesses are collecting and processing more data than ever. With the explosion of generative AI, as much as we are in an AI revolution, we are also in a data revolution. We can’t have powerful LLMs without access to massive data.
Companies leverage their data to drive business decisions, product direction, help serve customers better, and even create new types of consumer experiences. However, as discussed, not all data is created equal, some data, like PII, is special.
Over time, we’ve recognized that other forms of data like encryption keys, secrets, and identity are special and need to be treated that way. There was a time when we stored secrets in our application code or database. We eventually realized that was a bad idea and moved them into secret managers.

Approaches to managing different types of sensitive data.
Despite this progress, we are still left without an accepted standard for the storage and management of sensitive PII data. PII deserves the same type of special handling. You shouldn’t be contaminating your database with customer PII.
Luckily there’s a solution to this problem originally pioneered by companies like Netflix, Google, Apple, and Goldman Sachs and now touted by the IEEE as the future of privacy engineering, the PII Data Privacy Vault.
The PII Data Privacy Vault
A data privacy vault isolates, protects, and governs access to sensitive customer data (i.e. PII) while also keeping it usable. With a vault approach, you remove PII from your existing infrastructure, effectively de-scoping it from the responsibility of compliance and data security.
A vault is a first principles architectural approach to data privacy and security, facilitating workflows like:
- PII storage and management for regulated industries
- PCI storage and payment orchestration
- Data residency compliance
- Privacy-preserving analytics
- Privacy-preserving AI
Let’s go back to our example from earlier where we were collecting a phone number from the front end of an application.
In the vault world, the phone number is sent directly to the vault from the front end. From a security perspective, we ideally want to de-identify sensitive data as early in the life cycle as possible. The real phone number will only exist within the vault, it acts as a single source of truth that’s isolated and protected outside of the existing systems.
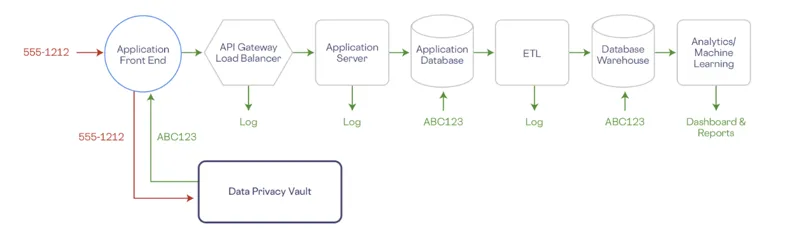
Example of using a data privacy vault to de-scope an application.
The vault securely stores the phone number and generates a de-identified reference in the form of a token that gets passed back to the front end. The token has no mathematical connection to the original data, so it can’t be reverse engineered to reveal the original value.
This way, even if someone steals the data, as what happened with the Capital One data breach, the tokenized data carries no value. In fact, Capital One was fined only because they failed to tokenize all regulated data, some records were purely encrypted and those records were compromised.
Revealing Sensitive Data
While it’s great to securely store sensitive data, if we simply lock it up and throw away the key, it’s not super useful. We store all this customer PII so we can use it.
For example, we may need to reveal some of the data to a customer support agent, an IT administrator, a data analyst, or to the owner of the data. In this case, if we absolutely need to reveal some of the data, we want to re-identify it as late as possible, for example during render. We also want to limit what a user has access to based on the operations they need to perform with the data. While I might be able to see my full phone number, a customer support agent likely only needs the last four digits of my phone number and an analyst maybe only needs the area code for executing geo-based analytics.
The vault facilitates all of these use cases through a zero trust model where no one and no thing has access to data without explicit policies in place. The policies are built bottoms up, granting access to specific columns and rows of PII. This allows you to control who sees what, when, where, for how long, and in what format.
Let’s consider the situation where we have a user logging into an application and navigating to their account page. On the account page, we want to show the user their name, email, phone number, and home address based on the information they registered with us.
In the application database, we’ll have a table similar to the one shown below where the actual PII has been replaced by de-identified tokens.

Example of users table within the application database.
As in the non-vault world, the application will query the application database for the user record associated with the logged in user. The record will be passed to the front end application and the front end will exchange the tokens for a representation of the original values depending on the policies in place.
In the image below, the front end already has the tokenized data but needs to authenticate with the vault attaching the identity of the logged in user so that access is restricted based on the contextual information of the user’s identity. This is known as context-aware authorization.
Once authenticated and authorized, the front end can directly call the data privacy vault to reveal the true values of the user’s account information. But the front end only has access to this singular row of data and it's limited to the few columns needed to render the information on the account page.

Example of revealing sensitive data for a single record.
Sharing Sensitive Data
No modern application exists in a silo. Most applications need to share customer PII with third party services to send emails, SMS, issue a payment, or some other type of workflow. This is also supported by the vault architecture by using the vault as a proxy to the third party service.
In this case, instead of calling a third party API directly, you call the data privacy vault with the de-identified data. The vault knows how to re-identify the PII securely within its environment, and then securely share that with the third party service.
An example of this flow for sending HIPAA compliant forms of communication is shown below. The backend server calls the vault directly with tokenized data and the vault then shares the actual sensitive data with the third party communication service.

Example of using a vault to send HIPAA compliant communication.
Final Thoughts
We’ve come a long way since building business applications in the 1980s, but we’ve failed to evolve our thinking regarding how we secure and manage customer PII. Point solutions like firewalls, encryption, and tokenization alone aren’t enough to address the fundamental problem. We need a new approach to cut to the root of the Cheese and Diamond Problem.
Not all data is the same, PII belongs in a data privacy vault.
The data privacy vault provides such an approach.
It's an architectural approach to data privacy where security is the default. Multiple techniques like polymorphic encryption, confidential computing, tokenization, data governance, and others combine with the principle of isolation and zero trust to give you all the tools you need to store and use PII securely without exposing your systems to the underlying data.
If you have comments or questions about this approach, please connect with me on LinkedIn. Thanks for reading!