
Understanding Tokenization vs. Encryption and When to Use Them
Tokenization and encryption are data protection techniques used to protect sensitive information. This post provides an overview of how they work, their strengths and limitations, and guidelines on where and how to use them.
What is data encryption?
Data encryption has a history that goes back to the ancient world. Early forms of encryption used a “cipher” to replace one letter or symbol for another when encrypting a message into ciphertext, unreadable text which can later be decrypted to the original plaintext using that same cipher.
Encryption and decryption have existed for millennia and have an entire branch of mathematics devoted to them: cryptography.
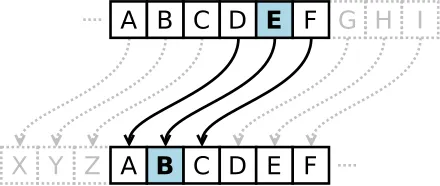
[image source: wikipedia] The Caesar Cipher is one of the simplest and most widely known encryption techniques. It is a type of substitution cipher in which each letter in the plaintext is replaced by a letter some fixed number of positions down the alphabet. For example, with a left shift of 3, D would be replaced by A, E would become B, and so on.
Classical cryptography continued to develop over time with the introduction of keys - secret codewords required to use the cipher - and more complex patterns and technologies, ultimately leading to the invention of the computer which changed everything. Simple ciphers could now be “cracked” (thanks, Alan Turing!), leading quickly to the development of “strong cryptography” and computer encryption.
Encryption uses very large keys and intentionally-complex algorithms, with data converted into ciphertext in order to transmit sensitive information.
To decrypt ciphertext into plaintext, the receiver must have access to the ciphertext data and the encryption key used to protect it.
How does data encryption work?
With encryption, the original data is still present in the encrypted ciphertext. If a bad actor were to come into possession of an encryption key or – with enough time and determination – mathematically figure out the encryption algorithm and key on their own, the sensitive data could be decrypted.
The stronger an encryption algorithm and key are, the harder it is to hack the encryption. Bad actors know that computers are only getting more powerful over time, which has led to the rise of the “harvest now, decrypt later” approach: attackers steal encrypted data which they can brute-force decrypt with future computing advancements. And with recent advancements in quantum computing, that vulnerable future appears to be getting closer to reality.
For this reason, encrypted data still holds value, so governments and regulators consider encrypted data to be sensitive data subject to cross-border transfer restrictions and other compliance requirements.
What is tokenization?
Data tokenization is the process of exchanging something of value for a meaningless token. In privacy and security engineering, a “token” is a representation of data that, on its own, has no inherent meaning or exploitable value. De-tokenization, then, reverses the process in order to retrieve the token’s original value. When performing a web-based payment transaction, for instance, tokens are often used instead of plaintext payment card data to keep the card data safe.
Some use cases for tokenization include protecting payments card (PCI) data, personally identifiable information (PII), protected health information (PHI), and more.
How does tokenization work?
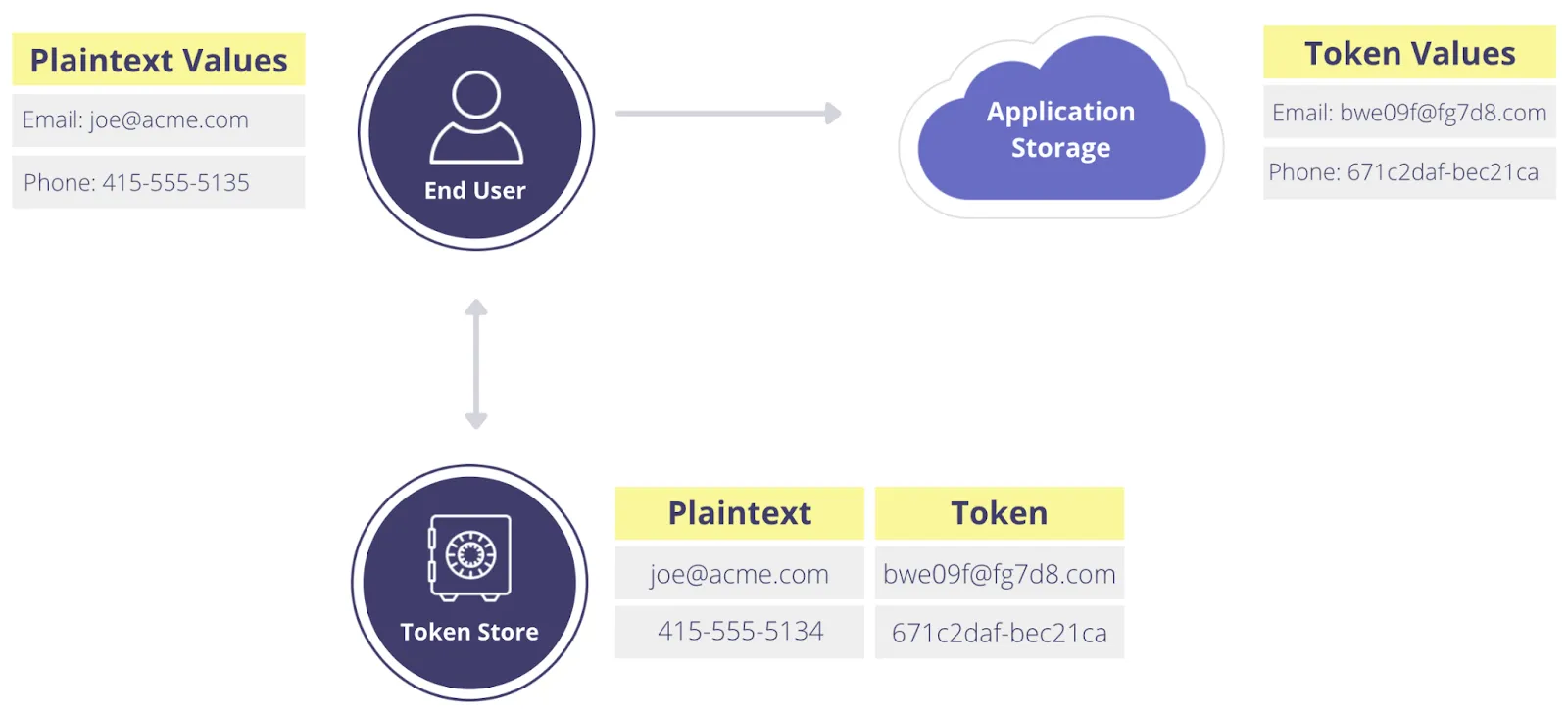
With tokenization, the token can be referenced in multiple systems and services, and can even be passed into an analytics pipeline, without compromising the privacy or security of the original data. The actual data is stored somewhere secure and is only used when absolutely necessary with a token redemption process called detokenization.
A tokenization scheme provides a one-to-one mapping: one token corresponds to one sensitive data element, like a name or PAN. Importantly, a token cannot be detokenized without access to the tokenization system and token map. If a bad actor were to breach a database of tokens, they could not do anything useful with the tokens because they wouldn’t have the mapping to the data the token represents without access to the detokenization process. Essentially, tokenization is about substitution and isolation of sensitive data elements.
For more information on tokenization specifically, check out Demystifying Tokenization: What Every Engineer Should Know.
Understand when vaultless tokenization falls short. Get the guide →
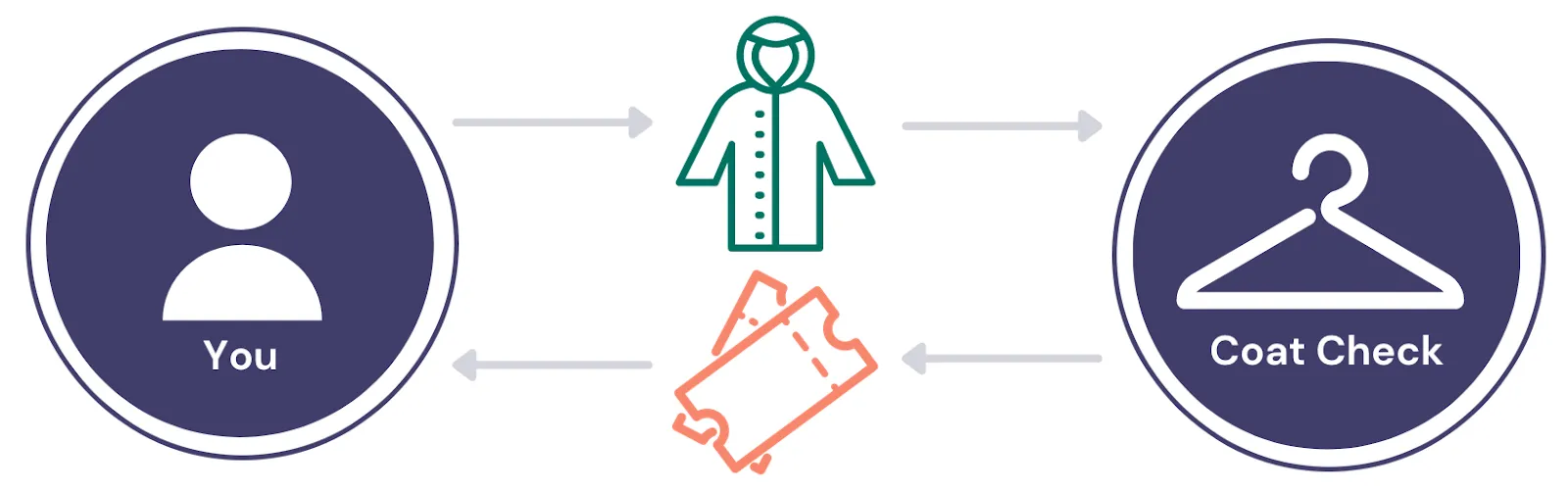
An Example of Tokenization: Coat Check System
A simple example of tokenization is a coat check system. You don’t want to carry your coat around so you decide to check it. At a coat check, you swap your coat for a ticket that you will need to present later in order to retrieve your coat. Should you forget to retrieve your coat, the coat check ticket will not keep you warm once you leave the establishment – on its own, the ticket can’t perform the function of the coat it represents nor can you somehow turn the ticket into a coat. In order to get your coat back, you have to exchange the ticket for it at the coat check, as shown in the following diagram.
Use Cases for Tokenization & Encryption
Let’s look at two real-world applications for tokenization & encryption:
- Payments
- Data Residency & Data Sovereignty
Tokenization & Encryption in Payments
The PCI Data Security Standards require that sensitive data is stored and transmitted only in encrypted form with access to the original data governed and audited extensively. All systems which touch the data are “in scope” of these compliance requirements and audits. In practice, maintaining PCI-compliant systems for storing card data is costly and complex.
By leveraging tokenization the scope of systems which need to be PCI-compliant and audited is dramatically reduced.
In PCI tokenization, tokens are passed between the merchant and the payment processor. The actual credit card information is only shared among the tokenization provider, payment processor, and the credit card networks.
Credit Card Tokenization
Here’s how credit card tokenization works in a typical payments workflow:
- A consumer gives the online merchant their PCI data – credit card number or PAN, CVV, and card expiry date – to purchase an item.
- The merchant registers that person’s credit card information with a tokenization service (such as the Skyflow Vault), and the tokenization service returns a token.
- The merchant stores the token.
- When it comes time to issue a transaction against the credit card, the merchant passes a token representing the credit card information to the payment processor (e.g., Stripe).
- The payment processor then transforms the token into meaningful PCI data, and sends that PCI data on to the credit card network (i.e., Visa).
- The credit card network then passes the PCI data to the issuing bank to complete the payment.
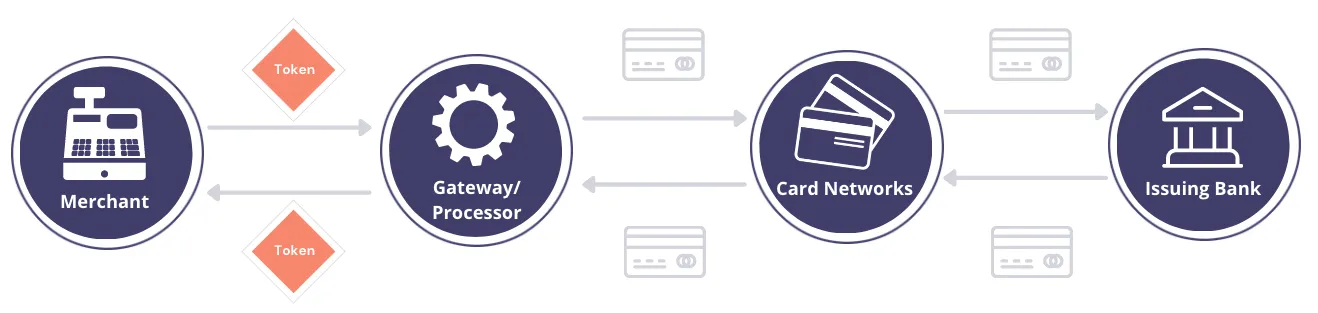
You can see how this is similar to the coat check example, except in this case, the exchange of tokens for sensitive credit card information also has a layer of governance and logging.
For more information about the latest developments in tokenization for payments, check out Network Tokenization: Everything You Need to Know.
Tokenization for Data Residency & Data Sovereignty
The advantages of tokenization go beyond consuming, storing, and processing payment information. Not only can tokenization protect sensitive data, tokenization can help keep personal data localized to help meet data residency requirements included in global privacy laws such as Brazil’s LGPD and Europe’s GDPR.
Data residency refers to the physical location of data. In other words, if the server hosting a database of user information is located in a data center in the United States, then the data residency would be described as the United States. With the advent of remote infrastructure and the growth of data collection, some countries have instituted laws governing where the personal data of their citizens can be physically stored.
Data sovereignty extends to the transfer of data. In addition to restricting where the data is stored data sovereignty restricts where the data can be transferred, generally requiring that sensitive data not leave the borders of the originating country. (learn more: China Data Residency: A Guide to Compliance with PIPL)
Both data residency and data sovereignty treat data as data, whether it is encrypted (ciphertext) or not (plaintext). Encryption without tokenization does not solve data residency.
Unlike encryption, true tokenization solves both data residency and data sovereignty. Tokens are used in place of sensitive data in the core backend infrastructure, databases, data lakes, analytics, and third party integrations so that PII can remain in one location while only non-sensitive tokens are transferred across borders.
Tokenization ensures that sensitive data remains in its country of origin without restricting the use of other, non-sensitive data across globally-distributed systems.
Here’s how tokenization is used in a typical data residency or sovereignty workflow:
- When you subscribe to an online streaming service, you provide PII such as your name, address, and phone number.
- The streaming service stores your PII in a data privacy vault in your region and gets a reference token in return.
- The streaming service then uses - and stores - the token instead of your PII. This way the streaming service - and all the services downstream of it - are protected from PII exposure. The PII stays safe in the vault, only to be “detokenized” when needed in its original form.
The following diagram shows how this works in the streaming service’s architecture.
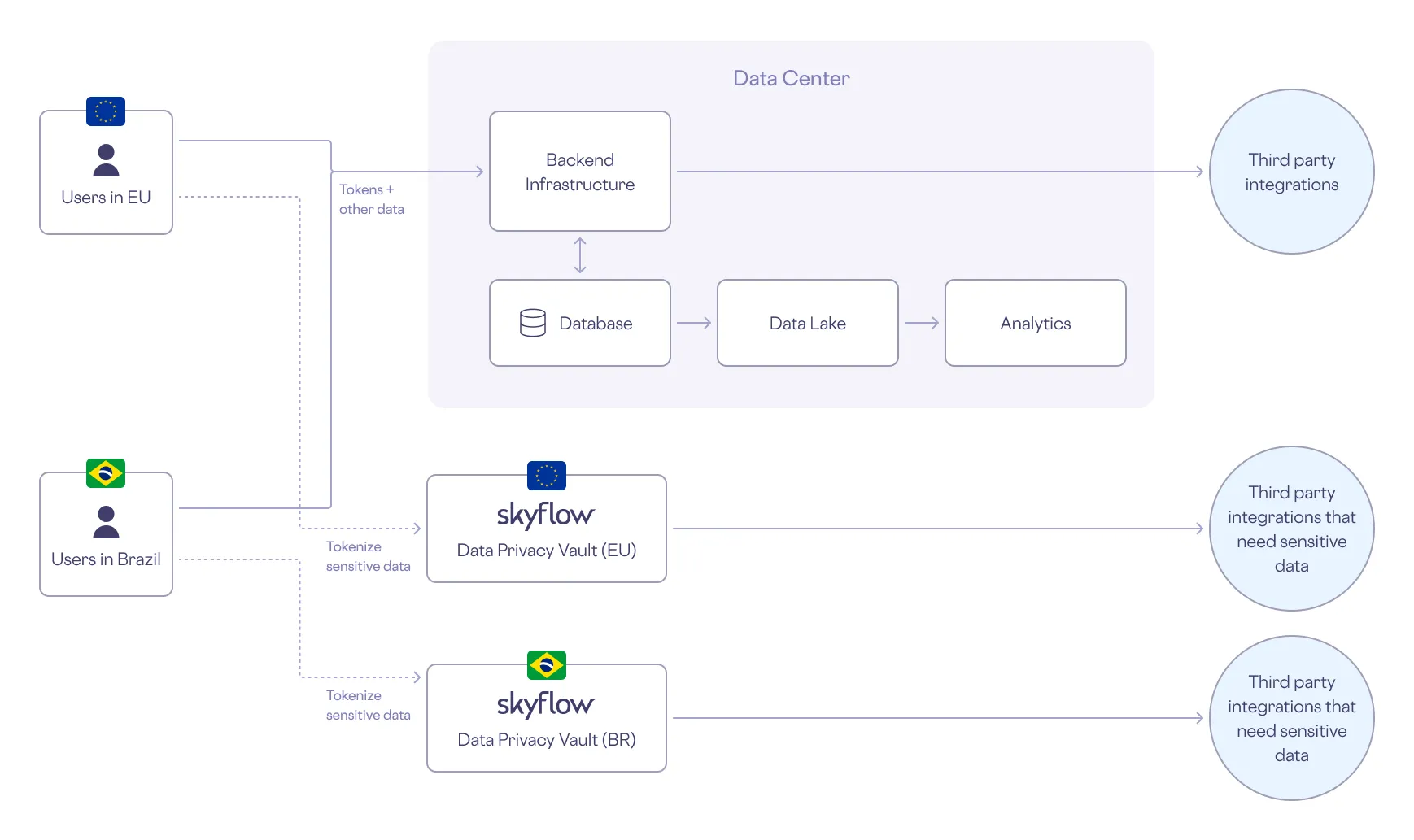
To learn more about data residency, see What is Data Residency, and How Can a Data Privacy Vault Help?
Understand when vaultless tokenization falls short. Get the guide →
Tokenization vs encryption: a comparison
Tokenization and encryption offer different, but complementary, solutions to the problem of protecting sensitive data.
To understand them better, it helps to look at them from several angles:
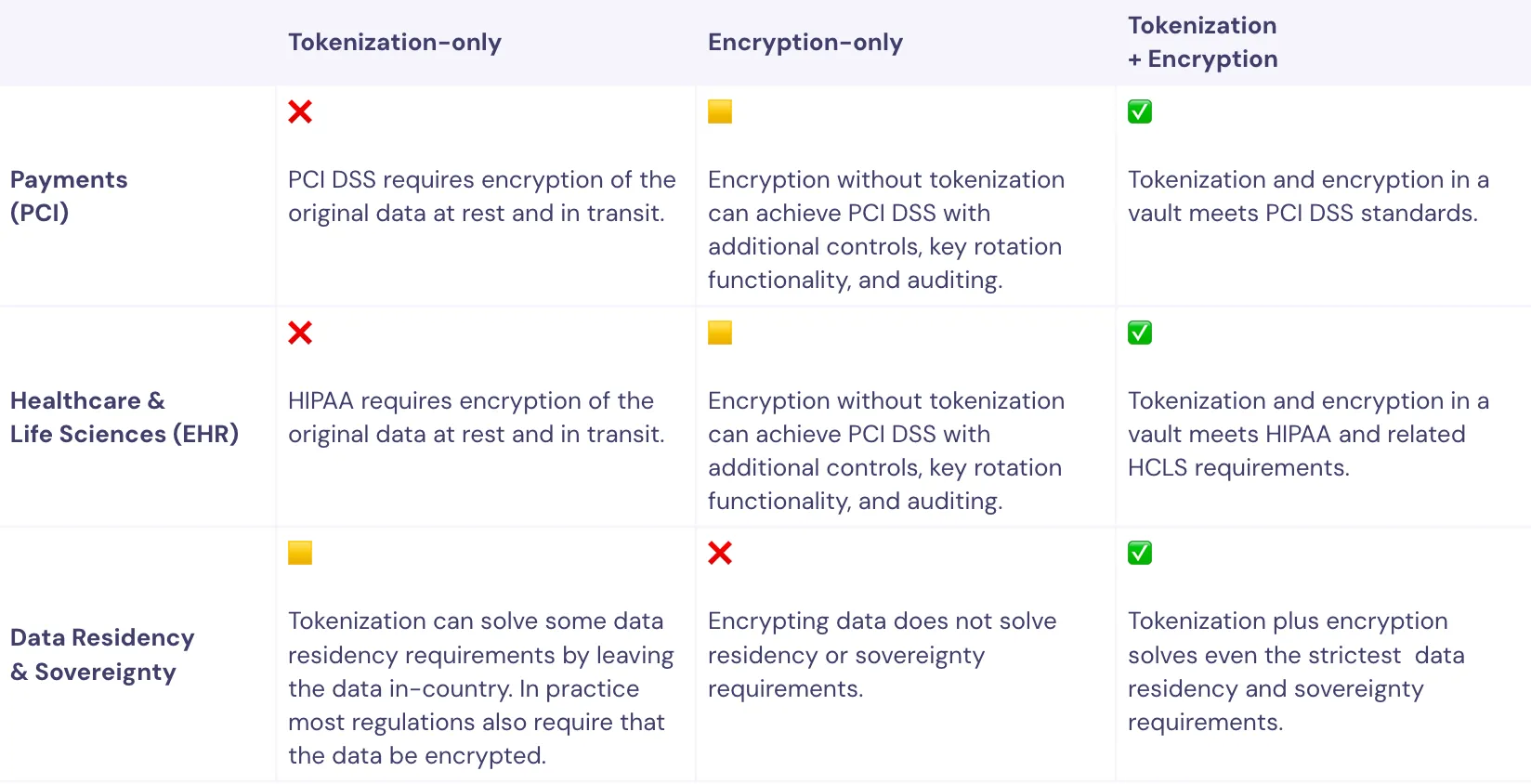
The strongest approach requires both tokenization & encryption
When it comes to ensuring data privacy, tokenization and encryption are complementary technologies and a solid data privacy strategy implements both. The data privacy vault from Skyflow not only provides the best of both tokenization and encryption, it secures your sensitive data and provides quantum-resistant strong encryption and seamless key management out of the box.
To provide yet another layer of protection Skyflow’s Vault also leverages polymorphic encryption to enable analytical operations on data without the need to ever decrypt the original data. More on that in another post.
To learn more about tokenization and encryption, check out:
- What is tokenization? What every engineer should know.
- What is polymorphic encryption?
- Partially Redacted Podcast: Introduction to Tokenization and Encryption with Skyflow’s Joe McCarron
- What is vaultless tokenization (and how to migrate off it)
Understand when vaultless tokenization falls short. Get the guide →